Cortex-M3 Architecture
* Update history
- 2013.3.27 : 초기 Release
1. Cortex-M3 Processor 소개
1.1 ARM Cortex-M3 프로세서란 무엇인가?
2. Cortex-M3 Procesor 개요
2.1 Cortex-M3 Procesor Overview
2.2 Cortex-M3 Processor Block Diagram
3. Cortex-M3 Processor Architecture
3.1 Register
3.2 Operation Mode
3.3 Stack
3.4 Cortex-M3 Memory Map
3.5 Bit Banding
3.6 System Timer(SysTick)
4. Nested Vectored Interrupt Controller
4.1 NVIC
4.2 Interrupt Response
1. Cortex-M3 Processor 소개
1.1 ARM Cortex-M3 프로세서란 무엇인가 ?
Cortex-M3 Processor는
ARMv7-M profile 프로세서로 low gate count, low interrupt latency, and low-cost 의 특징을 갖는 기존의 8Bit Microcontroller(AVR, PIC, 8051 등) 시장에 대응하는 Processor 입니다. 또한 Cortex 는 각각 다른 특징을 갖는 3가지의 Profile 이 있습니다.
(1) A profile (ARMv7-A) : Application Profile
- For sophisticated, high-end applications running open and complex operating systems
- ARM, Thumb, Thumb-2 instruction sets
- S5PC100, S5PV210, OMAP3530 ..
(2)
R profile (ARMv7-R) :
Real-time Profile
- For real-time system
- ARM, Thumb, Thumb-2 instruction sets
(3) M profile (ARMv7-M) :
Microcontroller Profile
- For cost-sensitive and microcontroller applications
- Thumb-2 instruction set only
- Banked Stack Pointer (SP) only.
- Hardware divide instructions, SDIV and UDIV (Thumb-2 32-bit
instructions).
- Handler and Thread modes.
- Thumb and Debug states.
- Interruptible-continued LDM/STM, PUSH/POP for low interrupt latency.
- Automatic processor state saving and restoration for low latency Interrupt
Service Routine (ISR) entry and exit.
- Support for ARMv6 unaligned accesses.
- Support Nested Vectored Interrupt Controller (NVIC)
- STM32F, LPC111x Series
[ Cortex-M3 시리즈 Performance ]
2. Cortex-M3 Procesor 개요
2.1 Cortex-M3 Procesor Overview
(1) Thumb-2 Instruction Set Architecture
- 16, 32 bit 명령을 조합해서 사용할수 있습니다.
- No more mode switching
- 16-bit code density로 32-bit 명령 성능을 낼수 있습니다.
- 16-bit Thumb Instruction 과 하위 호환성이 있습니다.
(2) Harvard architecture
- Separate I&D buses allow parallel instruction fetching & data storage
- 명령어와 Data를 동시에 Fetch할수 있는 기능은 인터럽트 수행시 Latency를 줄일수 있는 중요한 feature 입니다.
(3) 3-Stage Pipeline with Branch Speculation
- Fetch, Decode, Execute
- 분기 예측을 할수 있다면 Pipeline 에서 Branch
시 Pipeline Flush를 줄일수 있어 시스템의 성능을 높일 수 있습니다.
(4) Integrated Nested Vectored Interrupt Controller(NVIC) for low latency interrupt processing
(5) Vector Table is address, not instruction
(6) Designed to be fully programmed in "C"
(7) System Timer(SysTick) for Real Time OS - Not Peripheral timer
(8) Bit Band Aliasing
(9) Interruptible-continued LDM/STM, PUSH/POP
(10) Support Unaligned Data Access
- Unaligned access를 지원해서 메모리 사용의 효율성은 높였지만 여전히 속도를 위해서는 Aligned access를 하는 것이 효율적 입니다.
2.2 Cortex-M3 Processor Block Diagram
(1) Cortex-M3 블럭도
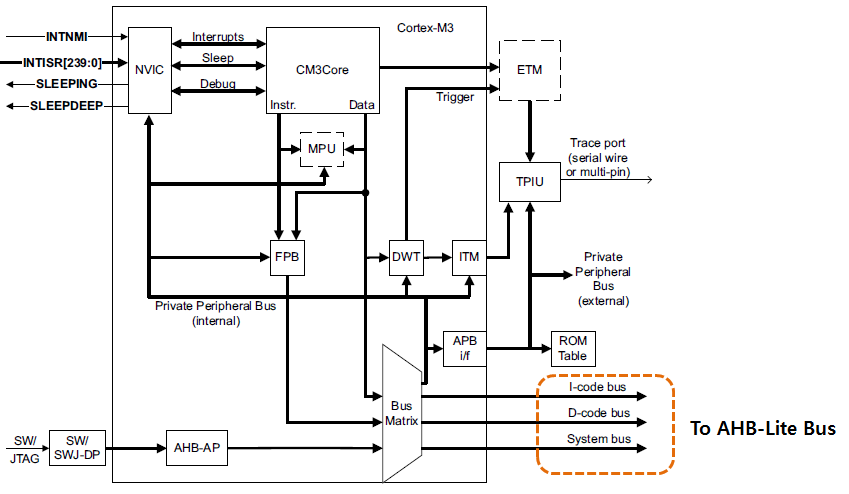
Cortex-M3 Core는 Bus Matrix( I-code, D-code, System Bus) 를 통해서 Cortex-M3 코어를 Base로 하는 CPU들(STM32F, LPC111x 시리즈 등)과 연결이 됩니다.
(2) Bus Matrix System
- ICode Bus : Instruction & Vector fetches from CODE space
(0x0000.0000 ~ 0x1FFF.FFFF)
- DCode Bus : Data & Debugging access to CODE space
(0x0000.0000 ~ 0x1FFF.FFFF)
- System Bus : Instruction & Vector fetches from System Memory space
Data & Debug accesses to System Memory space
System Memory( SRAM, External RAM )(3) STM32F 시리즈 블럭도
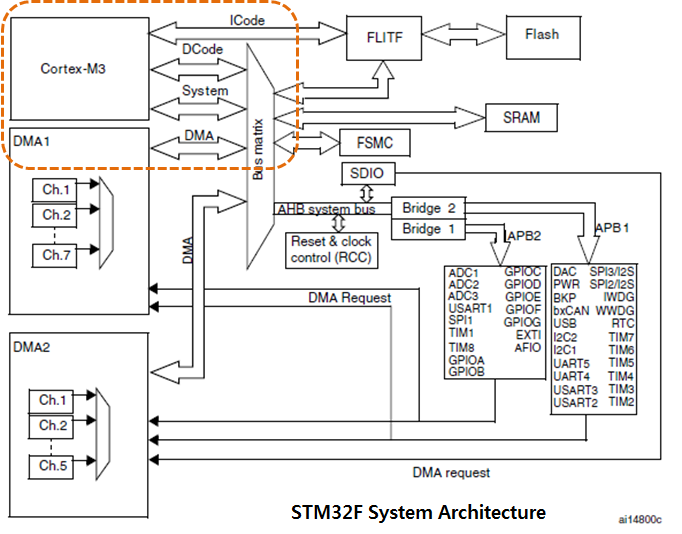
[ Cortex-M3 Core를 Base로 한 STM32F 시리즈 블럭도 ]
위의 블럭도에서 Cortex-M3 부분만 ARM사에서 디자인한 것이고 나머지 부분은 ST Microelectronics 에서 설계한 것입니다. Philips사의 LPC11x Cortex-M3 시리즈도 Cortex-M3 Core 부분은 STM32F 시리즈의 Core 와 동일하고 주변 Peripheral, interface bus 등의 부분만 다른 것입니다.
(4) Cortex-M3 와 ARM7 비교
ARM7TDMI |
Cortex-M3 |
|
| Architecture | ARMv4T(von Neumann) |
ARMv7M(Harvard) |
ISA Support |
ARM(32-Bit) & Thumb(16-Bit) need Mode Change |
Thumb-2 Only |
DMIPS/MHz |
0.74(Thumb)/0.93(ARM) |
Thumb-2(1.25) |
| Pipeline | 3-Stage | 3-Stage+Branch Speculation |
Interrupts |
IRQ/FIQ |
NMI,SysTick and up to 240 Interrupts. Integrated NVIC Interrupt Controller Up to 1-255 Priorities |
Interrupt Latency |
24~42 Cycles |
12 Cycles (6 when Tail Chaining) |
Memory Map |
Undefined | Architecture defined |
System Status |
PSR, 6modes 20 Banked regs |
xPSR, 2modes(Thread, Handler) Stacked regs(1 bank) |
Sleep Modes |
No |
Three |
3. Cortex-M3 Processor Architecture
3.1 Register
(1) General Register
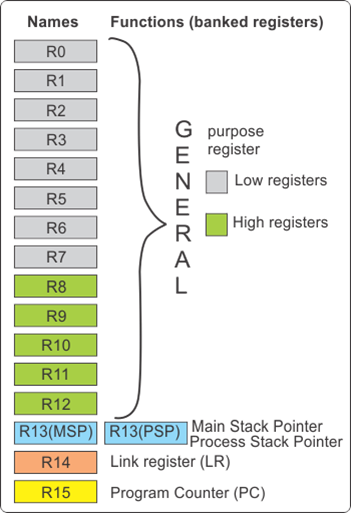
전통적인 ARM(ARM7,ARM9) 에서는 7개의 동작 모드별로 Banked Register 가 있었으나 Cortex-M3 에 와서는 R13(SP) 이 Main Stack Pointer와
Process Stack Pointer 로 구분되어 Banked Register로 존재하고 나머지 레지스터는 Cortex-M3 동작 모드(Thread Mode, Handler Mode) 에 상관없이 1개씩만 존재 합니다. 16-bit Thumb 명령어 에서는 R0 ~ R7 레지스터만 사용이 되고 32-bit
Thumb2 명령어에서는 R0 ~ R15가 모두 사용이 됩니다. Stack Pointer (R13) 는 항상 4-Byte정렬이 되어 운영 되어야 하므로 Stack Pointer의 하위 2비트는 항상 '2b00' 이 되어야 하겠지요. 그리고 Stack은 Full Descending 방식으로 운영이 됩니다.
Linked Register(R14) 는 전통적인 ARM과 마찬 가지로 BLX 명령어 사용시 복귀 할 주소가 저장 되어 있습니다. Program Counter(R15)는 당연히 현재 실행하고 있는 명령어의 주소(엄밀히 말하연 Pipeline 단계에서 Fetch 하고 있는 명령어의 주소)를 가지고 있습니다. 그러므로 실제 PC는 현재 실행하고 있는 명령어 다음 다음의 명령어의 주소가 저장되어 있습니다.
(2) Special Register
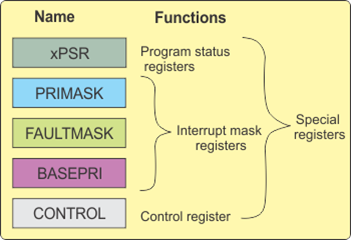
전통적인 ARM 에서는 CPSR(Current Processer Status Register) 이라는 특별한 상태 레지스터와 동작 모드별로 SPSR(Saved Processor Status Register) 이 존재 하였는데, Cortex-M3 에서는 Special Register 의 종류가 많이 늘어 났습니다. 하지만 기존의 CPSR 레지스터와 저장하고 있는 정보는 비슷합니다.
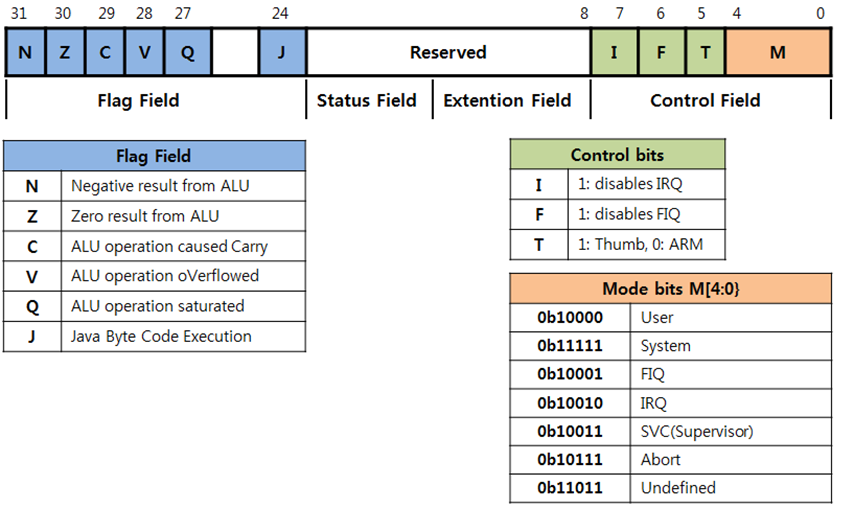
[ ARM7 에서의 CPSR 레지스터 ]
xPSR은 APSR, IPSR, EPSR 3개의 Spectial Register로 나누어 볼수 있습니다.
- APSR(Application Program Status Register)

현재 실행하고 있는 프로그램의 상태 정보를 담고 있습니다. 예를 들면 CMP 명령어와 같은 비교 문이나 ALU 연산의 결과가 APSR 레지스터의 Flag 비트를 업데이트 합니다.
* 어셈블리어
CMP R0, R1 ; R0 = 0, R1 = 1, R0 - R1 and update APSR Register
ADDMI R0, R0, R1 ; R0 = R0 + R1
SUBEQ
R0, R0, R1 ; R0 = R0 - R1
* C언어
if( R0 - R1 < 0 )
R0 = R0 + 1
else
R0 = R0 - R1
CMP 명령어는 결국은 R0 - R1 을 한 결과를 가지고 APSR 레지스터를 업데이트 합니다. 결국 0에서 1을 빼먼 -1이 되고 Negative "N" 이 APSR레지스터 31번 비트에 Set 이 됩니다. "N" Flag가 Set 이 되면
위의 명령어 중에서 ADDMI 명령어만 실행이 되고 SUBEQ 명령어는 NOP 명령어로 대체가 되어 실행이 되지 않습니다. ARM7에서는 CPSR 레지스터의 [31:27] 비트와 같은 역할을 합니다.
- IPSR(Interrupt Program Status Register)

이전의 ARM Processor는 인터럽트 컨트롤러가 ARM Core에 존재 하지는 않았습니다. 주로 CPU를 설계, 제조하는 반도체 Vendor에서 ARM Core의 외부에 CPU 설계시 추가하는 Peripheral들 중의 하나 였습니다. 그래서 IRQ가 발생하면 어떤 인터럽트가 발생 하였는지를 CPU에 존재하는 인터럽트 컨트롤러에서 INTOFFSET과 같은 ARM Core 외부의 SFT 레지스터에 저장이 되었습니다. 하지만 Cortex-M Profile 에서는 인터럽트 컨트롤러가
ARM Core 내부(NVIC)에 존재 합니다. IPSR은 현재 수행중인 Exception(Interrupt)의 번호를 저장하고 있는 레지스터 입니다.
- EPSR(Execution Program Status Register)

ICI(Interruptible-Continuable Instruction)/IT(If-Then) 2개의 중첩된 필드를 지니고 있는 레지스터 입니다. 전통적인 ARM 에서는 LDM, STM 명령어 수행중에 인터럽트가 발생을 하더라도 멈출수가 없었습니다. 명령어 Boundary에서 인터럽트 처리가 되기 때문에 LDM(POP), STM(PUSH) 명령어 수행이 끝나고 나서야 인터럽트를 처리할 수가 있습니다. 하지만 Cortex-M3 에서는 LDM(POP)/STM(PUSH) 명령 수행중에도 인터럽트 처리가 가능합니다.
LDMFD SP!, {R0, R1, R4-R6}
위와 같이 Multiple Load 명령어 수행시 R1을 Load 하는 중에 인터럽트가 발생을 하게되면 Cortex-M3 에서는 R1레지스터 까지만 처리한 다음 LDM 명령을 중단하고 현재 발생한 Exception(인터럽트) 처리를 끝내고 나서 중단 되었던 나머지 R4-R6 Load 명령을 수행하게 되는데, 이때 인터럽트를 끝내고 나서 중단 되었던 레지스터부터 다시 Load 명령어를 수행할 수 있도록 임시로 ICI 필드에 중단 지점의 레지스터 순서를 저장하고 있는 저장소가 바로 EPSR 레지스터의 ICI 필드 입니다. [15:12] 비트만 사용을 하고 나머지 비트 [11:10], [26:25] 필드는 사용하지 않습니다.
IT 필드는 Thumb-2 명령어인 If-Then 블럭의 Condition과 명령어의 순서 번호를 가지고 있습니다.
CMP R0, R1
ITTEE EQ
ADDEQ R2, R0, R1 ; R2 = R0 + R1
ADDEQ R2, R0, R3 ; R2 = R0 + R3
SUBNE R2, R0, R1 ; R2 = R0 - R1
SUBNE R2, R0, R3 ; R2 = R0 - R3
위의 어셈블리어 명령어들을 해석해 보면 R0 - R1 한 결과가 "0" 이면 ADDEQ 명령어 2개를 실행하고 "0" 이 아니면 SUBNE 명령어 2개를 실행 하라 입니다.
C언어로 표현하면 아래와 같습니다.
if( R0 == R1 )
{
R2 = R0 + R1
R2 = R0 + R3
}
else
{
R2 = R0 - R1
R2 = R0 - R3
}
If-Then 명령어 Block 수행중에
인터럽트가 발생하면 인터럽트 서비스 루틴으로 분기를 했다가 다시 If-Then 명령어 Block으로 복귀하여 인터럽트가 발생했던 지점의 다음 명령어 부터 수행해야 하는데 인터럽트 서비스 루틴으로 분기하기전에 IT 필드에 몇번째 명령어까지 수행했었는지를 잠시 저장하는 레지스터 입니다.
이때 IT[7:5] 비트는 Base Condition 정보 "CMP" 를 저장하고 있고 IT[1:0], IT[7:4] 비트는 If-Then 명령어 Block안의 ISR이 발생하기 전까지의 수행된 명령어 번호를 저장하고 있습니다. 또한 ICI/IT 는 EPSR 레지스터 안에서 같은 비트의 필드를 공유하고 있기 때문에 If-Then Block 에서 LDM/STM 과 같은 Multiple Load/Store 명령어를 사용하면 LDM/SDM 명령어 수행중에 인터럽트가 발생해서 인터럽트 서비스 루틴을 끝내고 복귀 했을때 수행했던 레지스터 번호부터 시작하지 못하고 처음부터 다시 LDM/STM 명령어가 수행되게 됩니다. EPSR 레지스터의 각 비트들을 표로 정리 하였습니다.
EPSR[26:25] |
EPSR[15:12] |
EPSR[11:10] |
IT[1:0] |
IT[7:4] |
IT[3:2] |
ICI[7:6] (‘00’) |
ICI[5:2] --> reg_num |
ICI[1:0] (‘00’) |
reg_num 는 LDM, STM 명령어 수행중에 인터럽트가 발생하여 잠시 중단 되었던 레지스터의 번호 입니다.
3.2 Operation Mode
전통적인 ARM에서는 동작모드가 7종류(User,System,Fiq,Irq,SVC,Abord,Undefined)가 있었습니다. Cortex-M3 에서는 Thread, Handler Mode 2가지로 축소 되었습니다. 그리고 Priviledge Level 에는 Privileged, Unprivileged 2가지의 경우가 있습니다. Cortex-M 이전의 ARM 에서는 USER Mode를 제외한 나머지 6개의 동작 모드가 Privilegdge Mode 입니다.
(1) Thread Mode
Exception 이 발생하지 않은 보통의 상태가 Thread Mode 입니다. Reset Exception 발생시(CPU 에 전원이 인가되어 초기 부팅시)에 Thread Mode + Privileged + Main_stack(Stack Pointer)로 시작하게 됩니다. 당연히 초기 부팅시에는 권한이 있는 모드로 실행이 되어야 하겠지요? 권한이 있는 모드로 부팅을 시작해야 H/W, S/W 설정을 끝내고 Unprivileged 모드로 전환을 해서 User Application을 실생 시킬수 있을테니까요. 그리고 한번 권한이 없는 모드로 전환이 되고 나면 일반적인 방법으로는 Privilege 모드로 전환할수 없습니다. Exception이 발생하여 Handler Mode(Handler Mode 에서는 항상 Privilege 모드)로 전환이 되거나 혹은 S/W 적으로 "SVC(Super Visor Call)" 명령어를 써서 SVC_Handler Exception 을 발생시켜서 Handler Mode의 서비스 루틴에서 MSR 명령어를 사용하여 Priviledge Mode로 변경 시켜야 합니다.
Privilege 모드에서 Unprivileged 로 전환하는 방법은 MSR 명령어를 사용하는 것입니다. 당연히 MSR 명령어는 Privilege 모드에서만 사용이 가능 합니다. Privilege level 변경 방법은 CONTROL Register 설명시에 예를들어 보도록 하겠습니다.
(2) Handler Mode
Thread Mode 에서 IRQ, Fault 등의 Exception 이 발생했을 경우 문맥 보존을 위해서 Stack에 {R0~R4, R12, LR, PC, xPSR} 레지스터가 Stack에 H/W적으로 PUSH(저장)가 되고 이와 병렬적으로 Thread Mode 에서 자동으로 Handler Mode 로 전환이 되면서 Cortex-M3 Architecture 적으로 미리 정의 되어 있는 Vector Table에 있는 Exception Handler 주소가 Fetch 되어 PC의 주소가 바뀌게 됩니다. 이렇게 Stack 메모리와 Vector Table Fetch 작업이 동시에 이루어 질수 있는 이유는 Cortex-M3 가 Havard Architecture 구조 이기 때문에 가능 합니다. Harvard Architecure는 구조적으로 Code, Data Bus 가 별도로 존재하는 구조 입니다. 반대로 Code와 Data Bus가 하나만 존재하는 구조를 Von-Neumann Bus 구조라고 합니다.
[ Von-Neumann bus 구조 - Wikipedia 참조 ]
[ Harvard bus 구조 - Wikipedia 참조]
당연히 Harvard Architecure 구조가 Von-Neumann Bus 구조보다 효율적이 겠지요. Handler Mode 에서는 권한 상태가 항상 Privilegde 모드 입니다. Handler 서비스 루틴이 끝나면 Exception 이 발생한 명령어의 다음 명령어로 PC가 복귀가 되고 그와 동시에 Stack 에서 POP 이 발생하여 이전에 Stack에 잠시 보관 되었던 {R0~R4, R12, LR, PC, xPSR} 레지스터들이 복구가 됩니다. {R0~R4, R12} 레지스터를 Cortex-M3 에서 자동으로 Stack에 저장하는 이유는 {R0~R4, R12} 레지스터들이 Scratch 레지스터들 이기 때문 입니다. 자세한 사항은 아래 AAPCS Register 부분을 참조하세요.
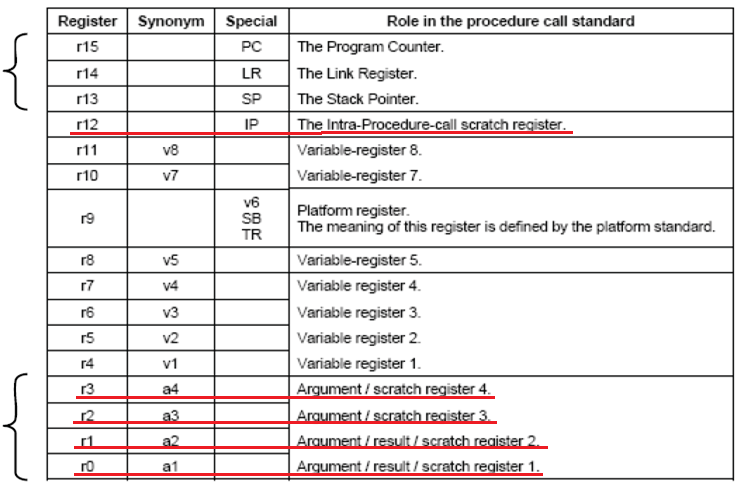
3.3 Stack
Cortex-M3 에서 Stack은 Main_stack, Process_stack 2개가 Banked 되어 존재하고 항상 4Byte Aligned 되어 있어야 합니다. 4Byte로 Aligned 되어야 한다는 것은 Stack Memory에 8Bit, 16Bit 데이터를 저장(PUSH) 하더라도 항상 32Bit 공간을 차지 한다는 것입니다. 전통적인 ARM에서는 7가지 동작모드별로 SP가 별도로 존재 하였습니다.
Reset Exception 발생시(CPU 에 전원이 인가되어 초기 부팅시)에 Thread Mode + Privileged + Main_stack 로 시작한다고 하였습니다. Reset Exception 발생시에 위의 사항 말고도 하는 일이 한가지 더 있습니다. 그것은 0x00 번지에 있는 주소를 Hardware 적으로 읽어와서 Main_stack Pointer를 Setup 하고 나서 0x4 번지 주소에 있는 Reset Handler Address( Progragm 시작 주소)를 읽어와서 PC 에 저장하는 것입니다. 이러한 이유때문에 Cortex-M3 에서는 실제로 프로그램의 시작 주소가 0x4 번지가 됩니다. 전통적인 ARM에서는 0x0 주소에 프로그램의 시작 포인터인 Reset Handler가 존재 하였고 0x0 주소의 내용은 명령어(Branch)가 존재 해야만 했으며 7가지 동작모드별로 Boot 코드에서 S/W 적으로 MSR 명령어를 사용하여 SP를 Setup 해야만 했습니다. 이에 비하면 Cortex-M3 의 Stack Pointer Setup은 H/W 적으로 이루어 지고 있어 개발자 입장에서는 많은 수고를 덜수가 있습니다. 참고로 STM32F 시리즈에서는 0x0 번지와 0x8000000 번지가 Alias 되어 있어 0x0 주소의 내용과 0x8000000 주소의 내용이 동일 합니다.
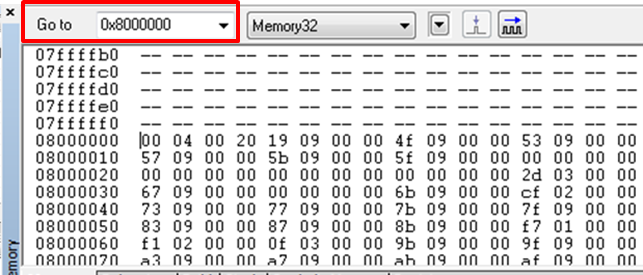
[ STM32F 에서의 0x8000000 주소의 Memory 내용 ]
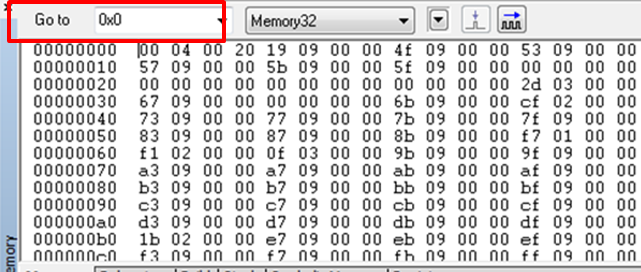
[ STM32F 에서의 0x0000000 주소의 Memory 내용 ]
Main_stack pointer 가 H/W 적으로 Setup 이 된다는 것은 0x04 번지에서 Segment 초기화를 끝내고 바로 main 함수로 분기하여 "C" Program 루틴에서 부터 부팅을 시작 할수 있다는 이야기 입니다.
여기서 Segment 초기화라는 용어가 나오는데 잠시 짚고 넘어 가도록 하겠습니다. 이전에 ARM Architecture 강좌에서도 한번 언급을 했었습니다.

main.c 파일을 컴파일하고 어셈블하여 main.o 파일이 생성이 된다면 .o 파일의 구조는 위와 같이 ZI(Zero Initialized), RW(Read Write), RO(Read Only) 영역등 으로 나누어져 생성이 됩니다. 결국 hex(bin) 파일의 구조는 main.o 파일과 같은 여러개의 *.o + *.a(라이브러리 파일) + Link Script(Scattor Loading) 파일이 조합이 되어 Linker에 의해 생성이 되는 것입니다.
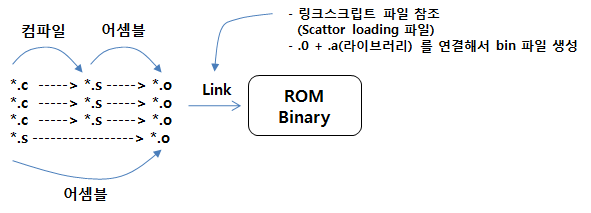
ZI, RO, RW 영역들을 Segment 라고 하며 이 Segment들이 타겟 시스템의 RAM, ROM 에 적당히 자리를 잡고 있도록 하는 작업을 Segment 초기화 작업 이라고 합니다. Segment 초기화 작업은 H/W 적으로 이루어 지지는 않습니다. Hex 파일을 JTAG 등의 장비를 이용하여 ROM 영역에 퓨징(Write)을 한 상태에서 부팅을 하면 Startup(Bootloader) 코드에서 ROM 메모리에서 RW 영역을 읽어와서 RAM에 복사해주고 ZI 영역은 모두 0x0 값으로 초기화 해주는 작업을 해주어야 합니다. 이러한 Segment 초기화 작업을 해주지 않으면 C 언어에서 사용하는 전역변수등에 올바른 초기값이 들어가 있지 않습니다.
hex(bin) 파일과 시스템의 RAM, ROM 과의 관계를 그림으로 표현해 보았습니다.
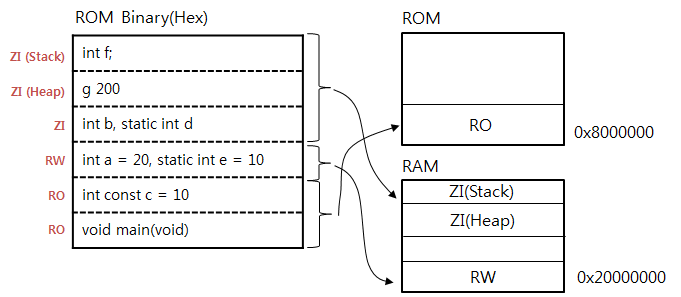
참고로 Cortex-M3 IAR 컴파일러는 부트코드 라이브러리에서 이 작업을 개발자 대신 해주고 있습니다. IAR Startup 코드중에서
__iar_program_start 라는 서브루틴 코드에서 아래 그림과 같은 라이브러리 루틴들이 순차적으로 호출 됩니다.
__iar_data_init3 가 Segment 초기화작업 서브 루틴 입니다.
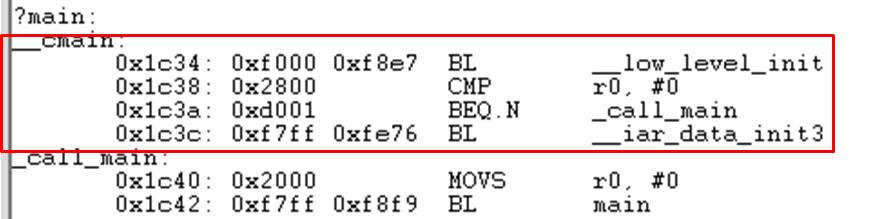
[ IAR 컴파일러 Cortex-M3 지원 코드 ]
(1) Main Stack setup
Main Stack 포인터는 부팅시에 H/W 적으로 0x0 번지에서 32Bit(4Byte) 값(Main Stack 포인터의 주소)을 읽어와서 자동으로 Setup 이 된다고 하였습니다. Cortex-M3 에서 0x0 번지에는 항상 Main Stack 의 주소가 있어야 합니다. 자동으로 Setup이 되지만 부팅 이후에 Main Stack 포인터를 변경하는 경우에는 MSR 명령어를 사용하면 됩니다.
MOV R0 , #0x20002000
MSR MSP , R0
(2) Processor Stack setup
보통의 경우에는 Main Stack만 사용해서 프로그램을 개발하면 됩니다. 하지만 RTOS등에서 커널은 Privilegde + Main Stack 을 사용하게 하고 User Application에서는 Unpriviledge + Processor Stack 을 사용하여 운영체제를 보호하고 싶다면 Processor_stack 포인터를 Setup 해야 합니다.
MOV R0 , #0x20001500
MSR PSP , R0
레지스터 설명에서 CONTROL레지스터에 대한 설명을 하지 않았었는데, 여기서 살펴보도록 하겠습니다.

CONTROL 레지스터는 Cortex-M3 Core 의 현재 권한 레벨(Privilege, Unprivileged)과 사용하고 있는 Stack을 저장하고 있는 Special Register 입니다.
- Bit[0] : 0 : privileged, 1 : Unprivileged
- Bit[1] : 0 : Use SP_main, 1 : Use SP_process
- Bit[2] : 0 : FP extension not active, 1 : Active
- Bit[31:3] : Reserved
(3) Stack Setup 예제
ARM에서 Stack은 Full-Descending 방식으로 운영되기 때문에 보통 RAM의 가장 높은 주소 영역에 Stack Pointer를 설정하게 됩니다.
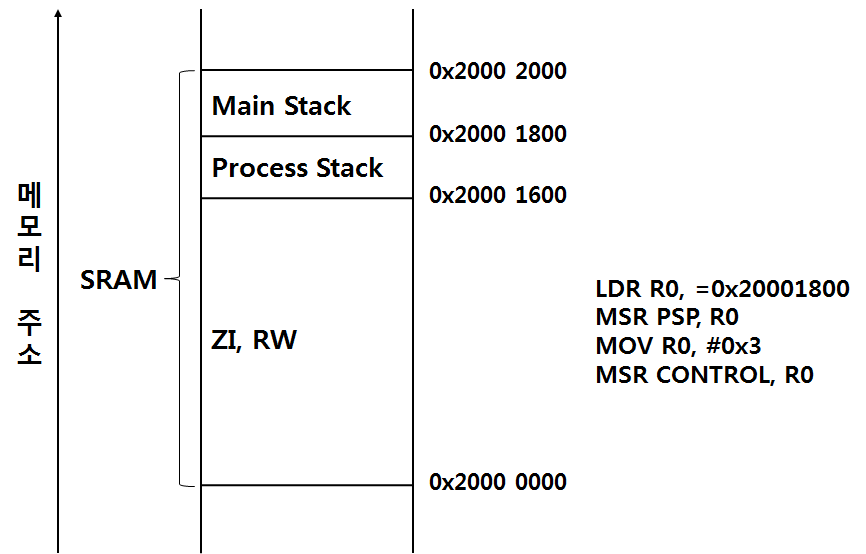
위의 예제에 있는 어셈블리어는 Processor Stack 포인터를 0x20001800으로 설정(MSR PSP, R0)하고 MSR 명령어를 사용해서 CONTROL 레지스터의 하위 [1:0] 비트를 "2b11" 로 설정하여Cortex-M3의 권한 레벨을
Unprivileged로 Stack 포인터는 Processor Stack을 사용하도록 하는 코드 입니다.
* Full-Descending 방식이란 ?
Stack 메모리에 데이터가 저장이 될때 Full-Descending 에서 Full 이라는 것은 Stack 동작이 끝나고 났을때 항상 SP는 유효한 데이터를 가르키고 있다는 것이고 Descending 이라는 것은 높은 주소에서 낮은 주소로 주소가 감소 하면서 데이터가 저장이 되는 방식 입니다. Stack PUSH 동작이 끝났을때 SP가 유효한 데이터를 가르키고 있으려면 데이터를 PUSH하기 전에 먼저 SP의 주소를 4Byte 감소시키고 나서 데이터를 저장 해야 합니다. 반대로 POP 동작에서는 데이터를 먼저 꺼내고 나서 SP의 주소를 4Byte 증가 시켜야 합니다. PUSH, POP 동작을 그림으로 예를 들어 보겠습니다.
- PUSH Operation
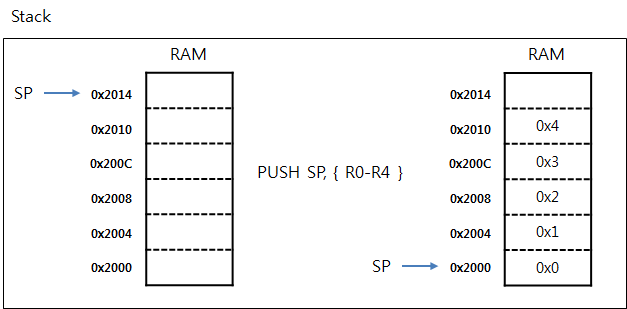
- POP Operation
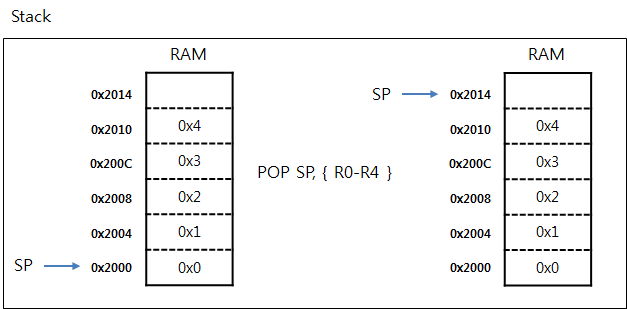
위의 그림에서 POP 동작이 끝난 이후에도 RAM STACK영역에는 데이터가 그대로 남아 있습니다. POP을 했다고 해서 메모리에서 데이터가 사라지는 것은 아니고 단지 SP 만이 변경된다는 사실을 알수 있습니다.
3.4 Cortex-M3 Memory Map
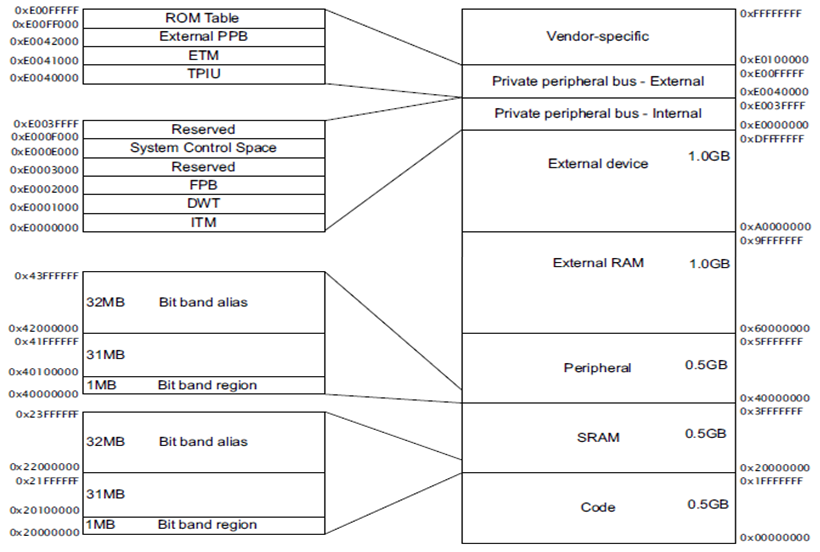
Cortex-M3 에서는 CODE 영역(ROM) 과 RAM(SRAM)의 주소가 Architecture 차원에서 정의가 되어 있기 때문에 Cortex-M3 Core를 기반으로한 CPU(ST, Luminsary, TI, Samsung 사의 Cortex-M3 CPU)들 사이에는 포팅 작업이 많이 쉬워 졌습니다. 이전의 전통적인 ARM에서는 CPU의 메모리 뱅크에 따라서 RAM의 시작주소가 같지 않을수 있고, Peripheral 들의 시작주소 또한 CPU마다 다를수 있습니다. 위이 Memory Map을 보면 32bit Core 이기 때문에 4GB 메모리까지 접근이 가능하고 SRAM, Peripheral 영역의 주소에 특이하게도 Bit band alias 영역이라는 것이 존재 합니다. 이 부분은 Bit Banding 장에서 자세히 설명 하도록 하겠습니다.
(1) STM32F103VC(High desnsity) 의 Memory Model
0x0800.0000 ~ 0x0801.FFFF ( FLASH )
0x2000.0000 ~ 0x2000.BFFF ( SRAM )
0x4000.0000 ~ 0x4002.3FFF ( Peripheral Memory Map )
0xE000.0000 ~ 0xE00F.FFFF ( Cortex-M3 Internal Peri. )
3.4 Thumb-2 Instruction Set
Cortex-M3 는 Thumb-2 명령어만 지원 합니다. 전통적인 ARM 에서는 16Bit Thumb 명령어와 32Bit ARM 명령어를 사용할 수가 있었는데, Thumb 모드에서는 16Bit 명령어만 사용할 수 있고 32Bit 명령어를 사용하기 위해서는 Mode Change(Thumb Mode --> ARM Mode)를 해야만 했습니다. Mode Change를 위해서는 BX 라는 분기 명령어를 사용해야만 했습니다. Thumb-2 명령어의 가장 큰 특징은 Thumb모드와 ARM모드 사이에 모드 전환 없이 16bit Thumb 명령어와 32Bit 명령어를 섞어서(Blend) 사용할수 있는 것입니다. 이러한 특징으로 Thumb 명령어만 사용했을때 보다 성능은 좋아지고 코드의 집적는 ARM 32Bit 명령어에 비해서 좋아졌습니다. Thumb-2 명령어는 기존의 Thumb 명령어와 하위 호환성을 유지 합니다.
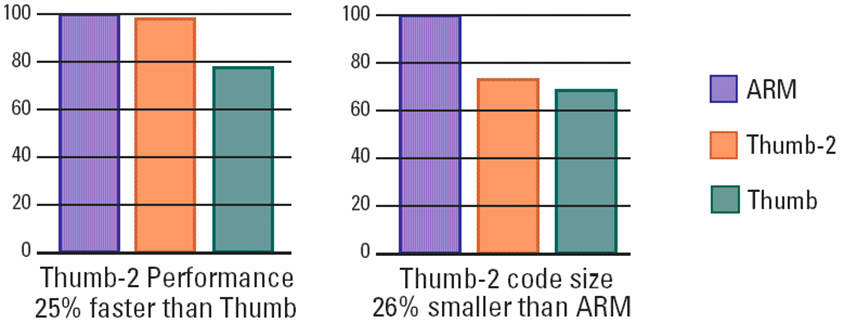
위의 그림은 명령어들 사이의 Performance와 Code size 를 표로 나타낸것입니다.
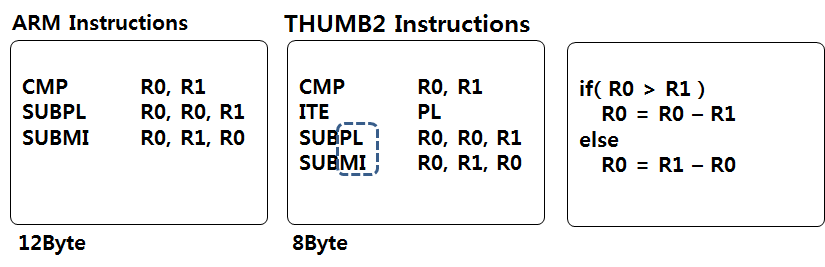
ARM 명령어를 사용했을 때와 Thumb-2 명령어를 사용했을때의 코드 사이즈를 비교해 보았습니다. 위의 어셈블리 명령어는 두수(R0, R1) 사이의 절대값을 구하는 명령어 입니다. "C" 언어를 참조하세요. 16Bit Thumb 명령어에서는 Conditional Execution 을 사용할 수 없습니다. 단, Thumb 명령어에서도 BX 명령어의 경우에는 Conditional Execution 을 사용할 수 있습니다.
3.5 Bit Banding
Cortex-M3 Memory Map을 설명할때 Bit band alias 영역이 있다고 하였습니다.
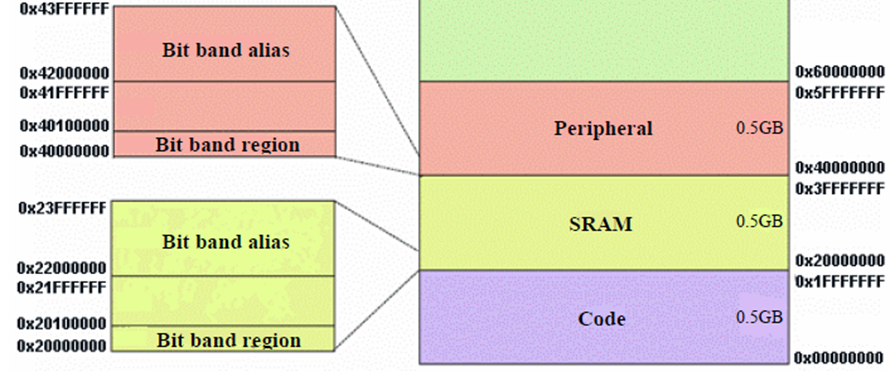
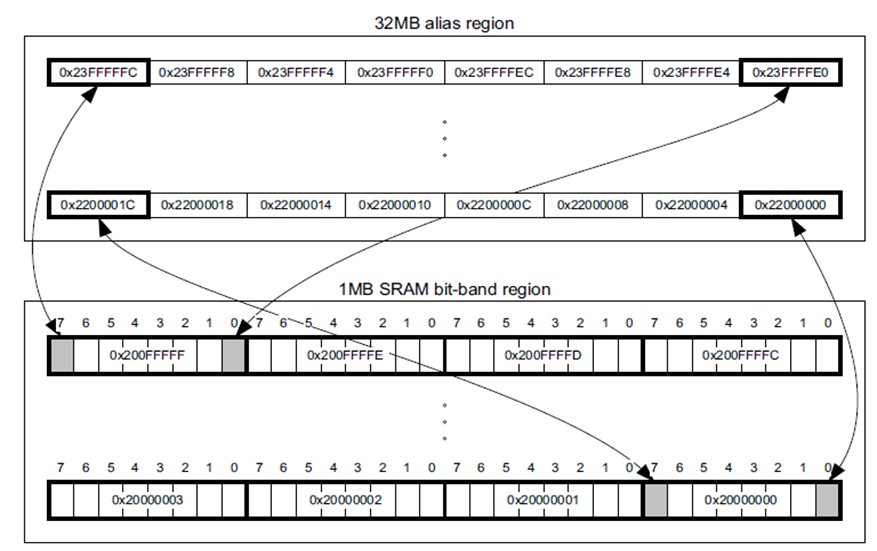
SRAM, Peripheral 영역에 존재하며 SRAM영역의 경우 0x22000000 주소에 '0' or '1' 을 Write 하면 0x20000000 주소의 실제 SRAM 의 [0] 번 비트 에 '0' or '1' 이 Write 되어 지는 것입니다. Write 뿐만이 아니라 0x22000000 주소의 Data 을 읽으면 0x20000000 주소의 SRM의 [0] 번 비트가 읽어 집니다. 즉 SRAM 1MB bit-band region 1비트는 32MB의 alias region 영역의 32bit(1 WORD) 와 Alias(동일하게 Mapping) 되어 있는 것입니다. 이러한 특징은 Peripheral 영역도 마찬가지로 적용이 됩니다. 그림으로 다시 보면 아래와 같습니다.
그러면 Cortex-M3 의 이런 특징이 있는 이유는 무엇 일까요 ? 예를 들면
0x4001180C 주소에 32bit GPIOE 그룹의 데이터 레지스터가 존재하고 있고 GPIOE2, 3, 4 포트에 각각 LED 가 연결되어 있다고 가정해 봅시다.
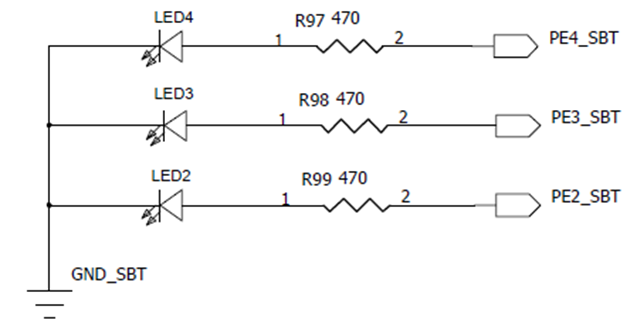
회로상으로는 위의 그림과 같습니다. 여기서 PE2, PE4의 상태는 건드리지 않고 PE3에 연결되어 있는 LED3만 ON(PE3 포트를 High)시키려고 한다면 Bit Banding이 지원되지 않는 시스템에서는 다음과 같이 코드를 작성해야 합니다.
(*(volatile unsigned *)0x4001180C) |= (0x1 << 2);
ARM의 Load, Store 구조에서 이것을 어셈블리어로 다시 작성해 보도록 하겠습니다.
LDR R0, =
0x4001180C ; R0 = 0x4001180C
MOV
R2, #0x4 ; R2 = 0x4
LDR R1, [R0]
; R0가 가르키는 주소에서 32Bit 데이터를 읽어와서 R1 레지스터에 저장
ORR R1, R2 ; R1 | R2
STR R1, [R0] ; R1레지스터의 값을 R0가 가르키는 주소에 저장
이와 같이 Bit Banding을 지원하지 않는 시스템에서는 레지스터에 메모리의 내용을 Register에 Load 해놓고
Bit wise 연산을 한 이후에 다시 STR 명령어를 사용해서 Register의 내용의 메모리에 저장하는 방식으로 해야만 합니다. ARM에서 연산 명령어들은 레지스터와 메모리의 내용으로 직접 연산을 할수가 없고 항상 메모리의 내용을 레지스터에 읽어와서 연산을 마친 이후에 메모리에 다시 저장하는 방식으로 사용해야 합니다. ARM은 Load/Store 방식이기 때문 입니다.
이번에는 Bit Banding 을 이용해서 같은 작업을 수행해 보도록 하겠습니다. 우선 C 코드로 작성해 보도록 하겠습니다.
(*(volatile unsigned *)(0x42000000 + (0x4001180C-0x40000000)*32 + 3*4)) = 0x0;
어셈블리어로 바꾸어 보면
; 상수들의 연산은 이해를 돕기위한 의사 코드임
; 실제로는 덧셈과 곱셈이 완료된 최종 상수값이 와야 합니다.
LDR R0, =
(0x42000000 + (0x4001180C-0x40000000)*32 + 3*4))
MOV R2, #1
STR R2, [R0]
Bit Banding이 지원되지 않는 시스템에서의 "LDR, ORR, STR" 3개의 명령어를 사용해서 구현 되었던 내용이 "STR" 명령어 1개를 이용해서 같은 작업을 하는 코드로 바꿀수가 있습니다. 이러한 특징은 수행 속도와 코드 집적도에서도 유리하며 이러한 기능이 주는 가장 중요한 특징은 바로 Atomic Operation 이 가능 하다는 것입니다. Atomic Operation 이라는 것은 더 이상 쪼개지지 않는 즉, 1개의 명령으로 기능이 수행되어 명령어 수행 도중에 인터럽트가 발생하지 않는것을 이야기 합니다. 여러가지 복잡한 인터럽트가 많은 시스템에서 Atomic Operation이 된다는 것은 전역 데이터 혹은 Peripheral의 SFR(Special Function Register)등에 접근할때 인터럽트에 의해서 데이터 처리 명령이 침해 당하지 않는 것을 보장 합니다. Atomic Operation이 아닌 명령어로 2개 이상의 인터럽트 서비스 루틴에서 공유로 사용하는 전역 데이터등을 처리하기 위해서는 일반적으로 데이터 처리전에 인터럽트를 Disable시키고 데이터 처리가 끝나면 다시 인터럽트를 Enable 시키는 방식으로 처리 합니다. 참고로 ARM 에서 인터럽트는 명령어 바운더리(Boundary) 에서 발생합니다. 명령어 Boundary라는 것은 명령어와 명령어 사이를 이야기 합니다. Cortex-M3 에서 LDM, STM(PUSH, POP)등 Multiple 데이터처리 명령을 제외하면 단일 명령어 수행중에 인터럽트가 발생을 하더라도 명령어 수행이 끝나면 인터럽가 시작 됩니다.
Bit band region과 Bit band alias 영역과의 Alias 관계를 정규화된 수식으로 표현하면 아래와 같습니다.
bit_word_offset = (byte_offset x 32) + (bit_number × 4)
bit_word_addr = bit_band_base + bit_word_offset
0x40000000 의 1번 비트에 해당하는 Bit Banding 주소는 0x42000000 + 32*0 + 4*1 의 수식이 적용 됩니다.
약간 복잡한듯 보이지만 잘 생각해 보면 계산식을 이해할 수 있습니다.
3.6 System Timer(SysTick)
Cortex-M3 Core 내부에 위치한 시스템 타이머 입니다. 24bit self-reloading down counter 이며 count가 0이 되면 SysTick Interrupt를 발생 시킬 수 있습니다. 모든 CPU에는 보통 타이머를 1개 이상은 가지고 있습니다. 하지만 SysTick이 일반 타이머와 다른점이라면 Core(정확히는 NVIC에 존재함)에 내장된 타이머 라는 것입니다. 이러한 특징은 Cortex-M3 Core를 사용한 모든 CPU는 모두 동일한 System Timer를 가지고 있다는 것입니다. 예를 들어 RTOS를 포팅한다고 했을때 필수적으로 주기적인 타이머 인터럽트가 필요한데 Cortex-M3 이전의 프로세서에서 RTOS를 포팅을 하는 경우에는 Core자체에 Timer가 없기 때문에 Vendor Specific한 Timer 를 사용하게 됩니다. 어떤 개발자는 Timer0를 사용할수도 있고 다른 개발자는 Timer1을 사용해서 포팅을 할수 있습니다. 이렇게 되면 같은 ARM Core를 사용했다고 하더라도 Processor들 간의 SW 포팅이 달라져야 합니다. 하지만 Cortex-M3 Core를 사용해서 RTOS 포팅을 한다면 당연히 Core에 내장된 공통적인 Timer인 System Timer를 사용해야 겠지요. System Timer에 대한 좀더 상세한 내용과 사용법은 Cortex-M3 Applicaiton 강좌에서 하도록 하겠습니다.
4. Nested Vectored Interrupt Controller
4.1 NVIC
Cortex-M3의 가장 중요한 특징중의 하나 입니다. Cortex-M3 이전의 전통적인 ARM 에서는 인터럽트 컨트롤러가 ARM Core의 외부에 위치해 있었습니다. 아래 그림은 ARM9 S3C2440 CPU 의 블럭도 입니다. 자세히 보면 Interrupt Controller 가 CPU의 Peripheral 로 구현이 되어 있습니다.
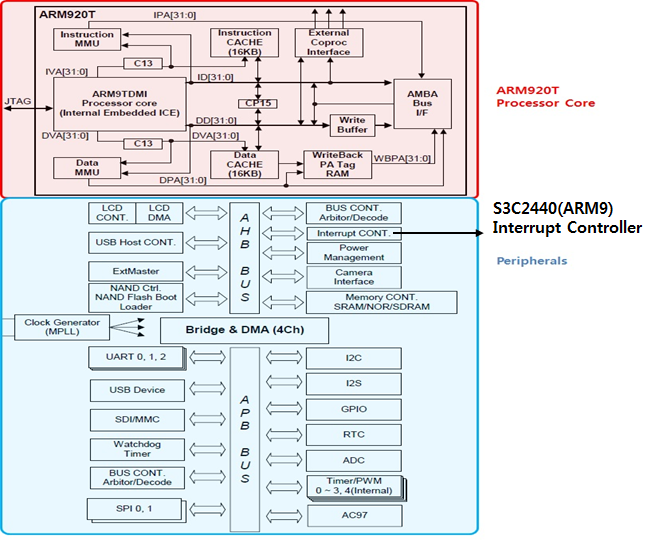
하지만 Cortex-M3 에서는 Interrupt Controller 가 ARM Core 의 내부 자원으로 들어와 있습니다. 그것도 Nested Vectored Interrupt Controller 라는 새로운 이름을 달고 말입니다. 아래 점선 박스 부분이 CM3Core(Cortex-M3 Core) 에 내장된 NVIC(Nested Vectored Interrupt Controller) 입니다. 참고로 아래 블럭도는 STM32F103x 시리즈 CPU 의 블럭도 입니다.
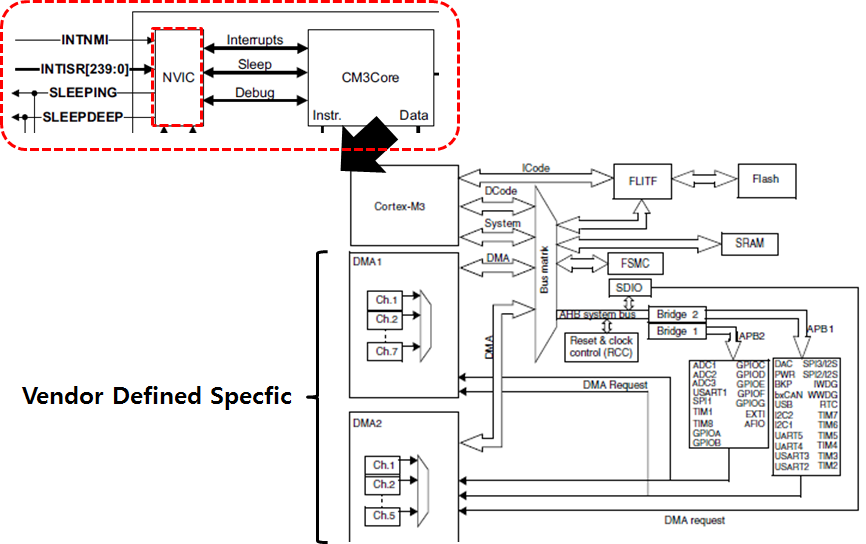
CM3Core 부분은 Vendor Defined Specific 부분이 아니라 Cortex-M3 CPU 들의 공통 사양 입니다. NVIC는 CM3Core 내부에 위치해 있습니다. 위에서 설명했던 Register(R0 ~ R15), Special Register(xPSR, CONTROL) 등은 모두 CM3Core 내부에 위치해 있는 것입니다. Nested Vectored Interrupt Controller 라고 하였는데 우선 Vectored 라는 용어부터 설명을 하도록 하겠습니다.
전통적인 ARM의 인터럽트 블럭도를 간략하게 표현해 보았습니다.
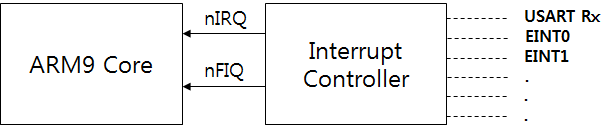
[ 전통적인 ARM CPU의 간략한
인터럽트 구성도 ]
전통적인 ARM에서는 인터럽트 컨트롤러가 ARM Core의 외부에 위치해 있으며 CPU의 여러개의 Peripheral들이 1개의 IRQ, FIQ 에 연결이 되어 있습니다. 이러한 이유로 만약에 EINT0 인터럽트가 발생을 하였다면 CPU 외부에 있는 인터럽트 컨트롤러를 통해서 ARM Core 에 Interrupt Request 가 전달되게 되는데 ARM Core 입장에서 보면 EINT0 이 발생하였는지 EINT1 이 발생한 것인지 알수 있는 방법이 없습니다. ARM Core 에서 알수 있는 방법은 S/W 적으로 ARM Core 외부에 있는 Interrupt Controller 의 SFR 레지스터에 접근하여 INTOFFSET(현재 발생한 인터럽트 번호가 저장되어 있는 레지스터) 을 읽어와서 인터럽트 번호를 확인하고 적당한 인터럽트 서비스 루틴으로 분기를 하는 것입니다. 하지만 Cortex-M3 에서는 이것보다 훨씬 효율적인 방법으로 인터럽트 서비스 루틴으로 분기를 합니다.
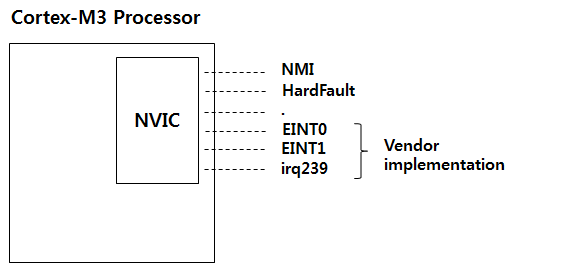
Cortex-M3 에서는 EINT0 인터럽트가 발생하면 이미 정해진 Interrupt Vector Table 에 있는 주소로 바로 분기 하며 이때 Special Register 중 IPSR 에 발생한 인터럽트 번호가 저장이 됩니다. 물론 인터럽트 서비스 루틴으로 분기 하기전에 문맥 보존을 위해서 H/W 적으로 {R0-R3,R12,LR,PC,xPSR} 레지스터들이 Stack에 저장이 되었다가 ISR 서비스 루틴이 끝나면 다시 H/W 적으로 Stack 에서 레지스터로 복원이 됩니다. 전통적인 ARM에서 문맥 보존은 S/W 적으로 개발자의 몫이었습니다. R0-R3, R12 를 Stack에 저장하는 이유는 앞에서 설명했듯이 Scratch Register 들 이기 때문입니다. Cortex-M3 에서 Exception의 종류는 최대 256개까지 존재 할수 있고 0 ~ 15 까지는 Cortex-M3 Internal Exception 이고 16번 부터 나머지 240개는 Core 외부 Exception 입니다. Exception Vector 0 ~ 15번 까지는 Cortex-M3 Core를 사용하는 모든 CPU는 동일하며 16 ~ 254 까지는 Vendor Specific 사양 입니다. 즉 CPU 마다 다를수 있다는 이야기 입니다.
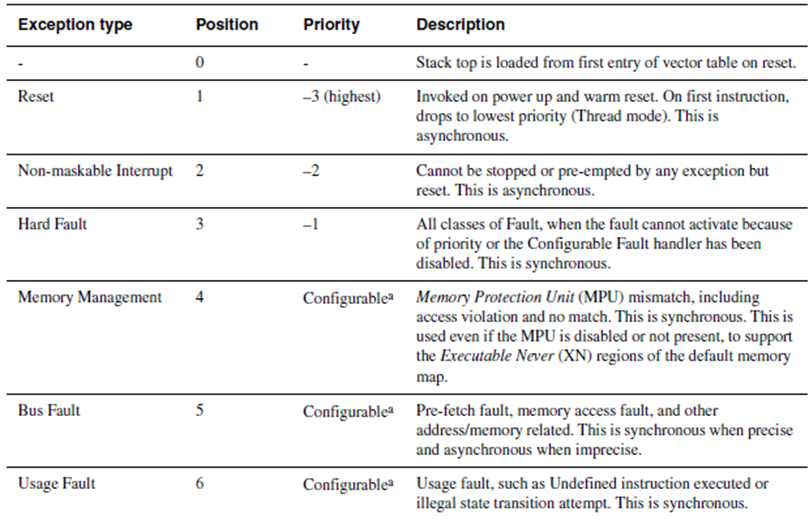
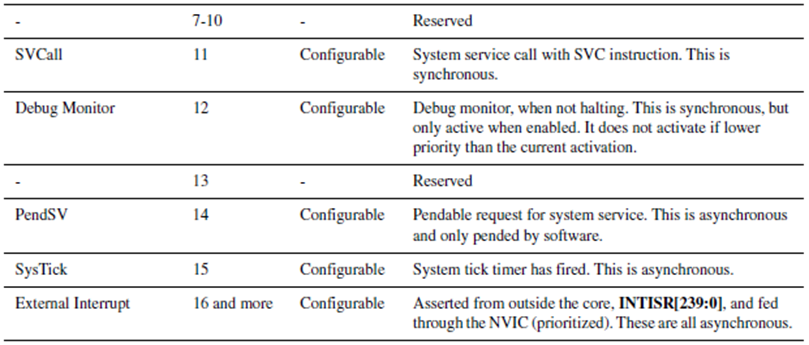
[ Cortex-M3 Vector Table ]
Vectored 라는 말은 0 ~ 255 까지의 Exception Vector 의 주소가 이미 정해져 있다는 말입니다. 그러므로 Exception 이 발생 했을때 어떤 Exception 이 발생했는지 여부에 상관없이 정해진 Vector Table의 주소에 있는 내용의 Address 로 바로 Exception 분기를 할수 있습니다.
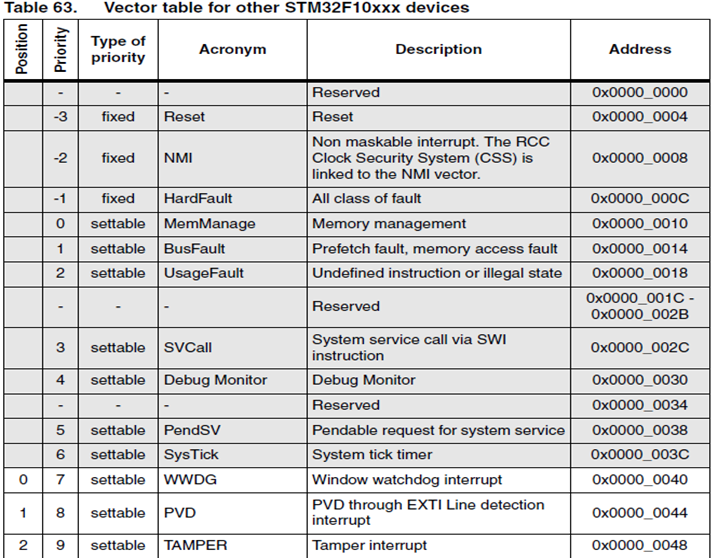
[ STM32F10x Exception Vector Table ]
위의 그림은 STM32F10x 시리즈의 Exception Vector Table 입니다. Cortex-M3 외부 인터럽트 벡터의 주소가 0x0000_0040 부터 시작하고 있네요. Reset시에 Vector Table의 Offset 주소는 0x0 이지만 Exception Vector Table의 시작 주소는 Vector Table Offset Register 를 수정하면 옮길수 있습니다.
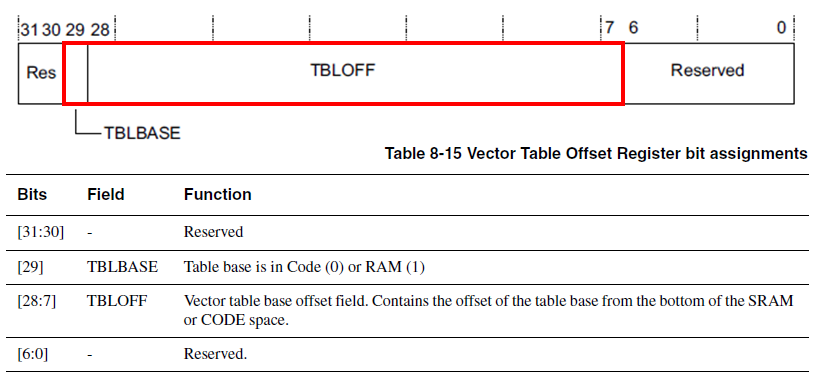
TBLBASE 의 값을 "1" 로 수정을 하면 Vector Table을 RAM 에 위치 시킬수도 있습니다. 그리고 TBLOFF 에 따라서 Vector Table 의 주소를 정해줄 수 있습니다.
다음으로 Nested 라는 용어를 살펴 보지요. Nested 라는 것은 사전적인 용어로는 "중첩되어 있는" 뭐 이러한 의미 입니다. Cortex-M3 에서는 인터럽트 수행중에 우선순위가 높은 인터럽트가 발생을 하면 현재 수행중인 인터럽트를 잠시 중단하고 나중에 발생한 우선순위가 높은 인터럽트를 먼저 수행한 이후에 잠시 중단 되었던 인터럽트 루틴으로 복귀하여 수행을 마치고 Normal 루틴으로 복귀를 합니다. 이러한 경우를 인터럽트가 중첩되었다고 합니다. 전통적인 ARM 에서 IRQ끼리는 중첩되는 경우가 없습니다. 모든 IRQ는 우선순위가 같기 때문에 중첩이 되지않고 IRQ 수행중에 다시 IRQ가 발생을 하면 나중에 발생한 인터럽트는 잠시 Pending상태에 들어 갔다가 현재 수행중인 인터럽트 서비스 루틴이 종료되면(엄밀히 말하면 인터럽트 서비스 루틴안에서 Pending Clear를 하는 시점에서) 잠시 Pending 되었던 인터럽트가 시작 됩니다. 인터럽트가 중첩되는 경우는 IRQ 수행 도중에 FIQ(Fast IRQ) 가 발생하는 경우에만 중첩이 됩니다. 인터럽트가 중첩이 되려면 인터럽트마다 우선순위가 달라야 하는데 Cortex-M3 에서는 최대 255 단계의 우선순위 레벨을 정해 줄수가 있습니다. 인터럽트 우선순위 단계는 AIRCR(Application Interrupt and Reset Control Register) 에 의해서 정해 줄수 있습니다.

PRIGROUP 부분에 0 ~ 7 사이의 값을 Write 할수 있습니다. PRIGROUP 에 의해서 Goup Priority(Pre-emption)과 Sub Priority의 경계를 나누어 줄수 있습니다.
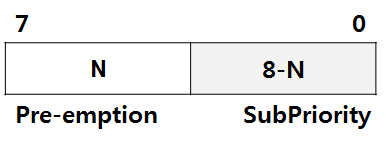
[ Cortex-M3 에서의 우선순위 그룹 ]
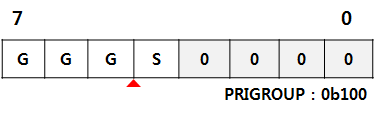
STM32F10x 시리즈에서는 0 ~ 7 비트중에서 4비트(상위 4 ~ 7 비트) 만 사용하여 Priority가 구현되어 있습니다. 하위 4비트는 H/W적으로 "0" 으로 Mapping 되어 있습니다. STM32F10x 시리즈에서 PRIGROUP의 값에 의해서 정해지는 Priority 단계를 표로 나타내 보았습니다.
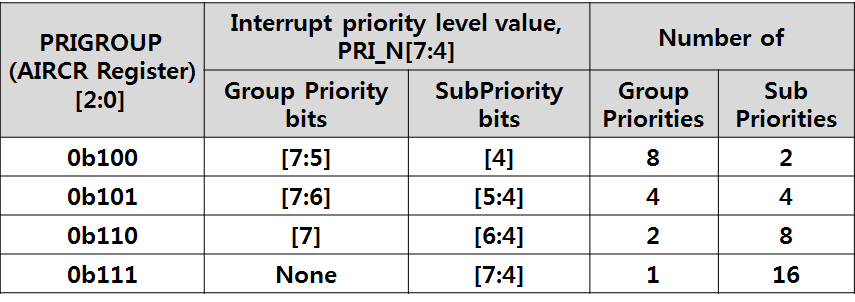
위의 표에서 PRIGROUP의 값이 0b100(4) 가 되면 Group Priorities로 8단계, Sub Priorities 로 2단계 까지 레벨을 정할 수 있습니다. PRIGROUP값에 의해서 Group Priorities와 Sub Priorities 의 레벨을 동적으로 조정 할수 있는 것입니다. Group Priorities와 Sub Priorities 에는 차이점이 있습니다. 예를 들어 PRIGROUP의 값이 0b100(4) 로 하고 EINT0, EINT1 에 대해서 아래 그림과 같이 우선순위 레벨을 정의해 주었다고 가정해 봅시다.
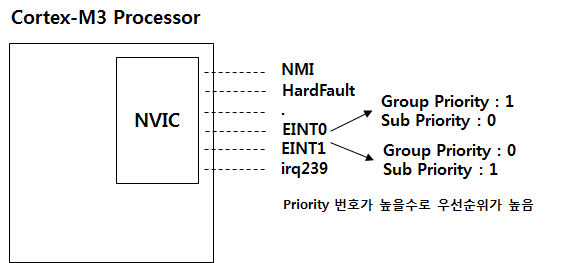
STM32F10x 시리즈에서는 상위 4bit만 이용하여 인터럽트 Priority를 구현 하였다고 하였습니다. PRIGROUP이 0b100(0x4) 일 경우에 아래 그림과 같이 Group Priority로 3bit, Sub Priority로 1bit 를 이용할 수 있습니다. 그러므로 Group Priority 값에는 0x0 ~ 0x7 사이의 값, Sub Priority 에서는 0x0 ~ 0x1 의 값이 올수 있습니다.
EINT0 의 인터럽트가 먼저 발생하여 인터럽트 서비스 루틴이 실행중에 있을대 EINT1 이 발생하면 EINT0의 Group Priority가 높기 때문에 EINT0 가 끝날때 까지 EINT1은 Pending 상태에 있다가 EINT0이 끝나면 EINT1 이 수행이 됩니다. 그러면 반대로 EINT1이 먼저 발생하여 인터럽트 서비스 루틴 실생중에 EINT0가 나중에 발생하면 어떻게 될까요 ? 이 경우에는 EINT0의 Group Priority가 높기 때문에 EINT1 수행을 잠시 중단하고 EINT0 를 수행한 이후에 중단되었던 EINT1이 수행이 됩니다. 여기서 알수 있는 것은 Sub Priority와는 상관없이 Group Priority에 의해서 인터럽트의 선점 우선순위가 달라 집니다. 그렇다면 Sub Priority는 어떤 용도로 사용이 될까요 ? EINT0, EINT1의 Group Priority 의 값이 같은 경우 동시에 인터럽트가 발생하면 Sub Priority가 높은 EINT1이 먼저 수행이 완료 되고 나면 EINT0가 나중에 수행이 됩니다.
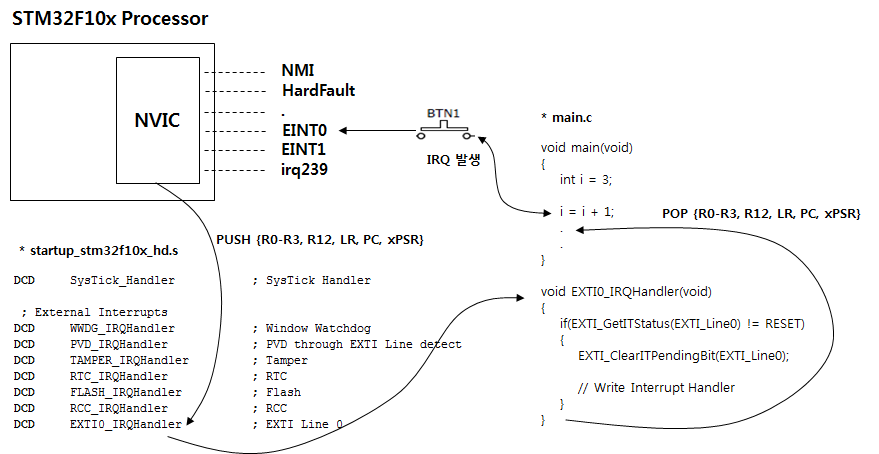
Exception이 발생하여 Exception Handler 루틴이 호출되고 다시 원래의 루틴으로 복귀 할때까지의 흐름을 그림으로 표현해 보았습니다.
다음 Chapter에서는 전통적인 ARM의 Interrupt Response에 비해서 Cortex-M3 에서 얼마나 좋아졌는지 살펴 보겠습니다.
4.2 Interrupt Response
(1) Tail Chaining
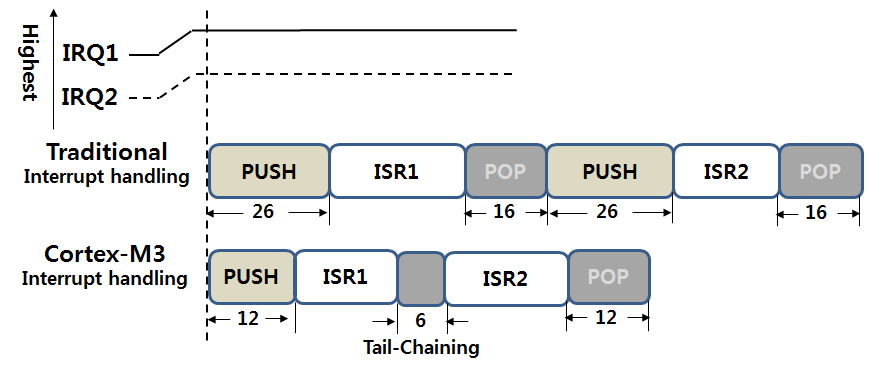
위의 그림을 보면 전통적인 ARM에서는 IRQ1이 IRQ2보다 우선순위가 높고 동시에 발생 했을 경우에 IRQ1이 먼저 수행이 끝나고 IRQ2가 수행이 됩니다. 이 과정에서 당연히 문맥 보존을 위해서 ISR1루틴으로 분기하기 전에 {R0-R3, R12, LR, PC} 레지스터등을 S/W 적으로 PUSH하고 ISR1 서비스 루틴이 끝날때 POP을 합니다. 그리고 다시 ISR2 루틴으로 분기하기 전에 PUSH를 하고 ISR2 루틴이 끝날때 POP을 하게 됩니다. 여기서 사실 ISR1 에서 ISR2 루틴으로 연결될때 중간에 있는 POP, PUSH는 하지 않아도 되는 불필요한 동작 입니다. 왜나먀면 이 과정에서 POP 하는 레지스터들은 ISR2 루틴이 끝나고 수행되는 POP과, PUSH 하는 레지스터들은 ISR1 시작전에 PUSH 되는 레지스터들과 동일하기 때문입니다. Cortex-M3 에서는 중복되는 중간 부분의 POP, PUSH를 생략하고 ISR1 루틴이 끝나면 6Cycle에 해당하는 Tail-Chaining 이 수행된 이후에 바로 ISR2 루틴으로 분기를 합니다. 참 효율 적이죠.. Tail-Chaining 부분에서 6Cycle 동안에 실제적으로는 하는 일은 Vector Table 에서 ISR2의 시작주소를 Fetech해오는 작업을 합니다.
(2) Preemption
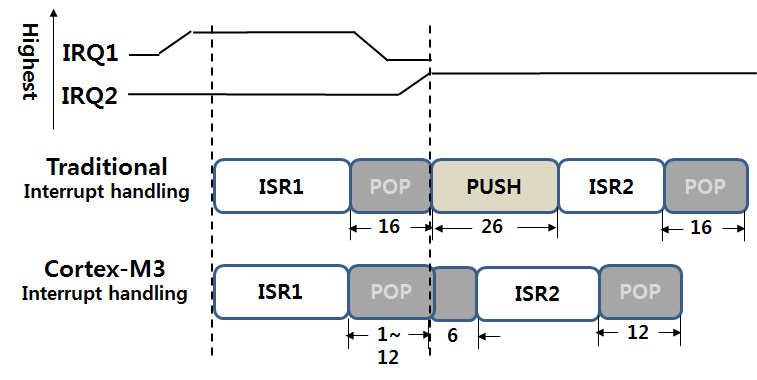
위의 경우는 ISR1 서비스 루틴 수행을 끝내고 문맥 보존을 위해서 POP을 수행하고 있는 도중에 IRQ2가 발생하는 경우 입니다. 전통적인 ARM에서는 Multiple Load 명령어 수행중에 인터럽트가 발생할수 없으므로 POP을 모두 수행하고 다시 ISR2를 위한 PUSH루틴으로 진입합니다. 하지만 Cortex-M3 에서는 POP(LDMFD) 수행중에도 인터럽트가 가능하기 때문에 ISR1과 ISR2 사이에 Tail-Chaining 이 발생하면 6Cycle 이후에 ISR2 루틴이 수행될수 있습니다.
(3) Late Arriving
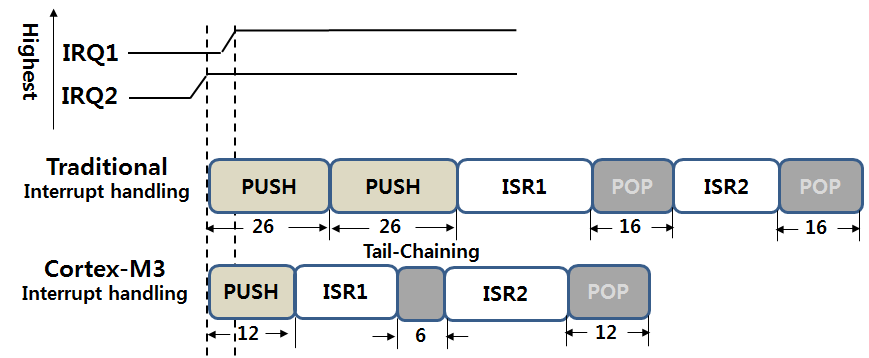
전통적인 ARM에서 IRQ2(IRQ) 수행을 위해서 PUSH 도중에 IRQ1 보다 우선순위가 높은 인터럽트(FIQ)가 발생하면 ISR2을 위한 PUSH작업이 끝나자 마자 ISR1을 위한 PUSH 작업이 진행이 됩니다. Cortex-M3에서는 ISR2를 위한 PUSH작업중에 IRQ2보다 우선순위가 높은 IRQ1이 발생하게 되면 IRQ1를 위한 PUSH작업은 진행되지 않고 바로 우선순위가 높은 ISR1이 수행되고 Tail-Chaining 이후에 ISR2를 수행하게 됩니다.
여기까지 Cortex-M3에 대한 구조는 어느 정도 정리가 된것 같습니다. 놓친 부분이 있다면 이후에 진행된 Cortex-M3 Application에서 예제를 통해서 다시 언급 하도록 하겠습니다. Cortex-M3 Application에서는 STM32F103VC Dragon 개발보드를 가지고 Cortex-M3 Architecture에서 이론으로 다루었던 내용들을 실습을 통해서 하나씩 공부해 보도록 하겠습니다. 실제 예제에서 컴파일러는 IAR 5.4 Evaluation 버젼을 사용할 것이고 Emulator로는 ARM-JTAG Light Edition 을 이용할 것입니다. 참고로 아래 그림은 우리가 Cortex-M3 Application 에서 사용하게될 개발보드의 사양 입니다.

참고로 다음 강좌인 Cortex Application에서 진행할 목차 입니다.
1. STM32F10x Overview
1.1 STM32F10x Block Diagram
1.2 STM32F10x Memory Map
1.3 STM32F10x Boot Modes
1.4 STM32F10x GPIO
2. STM32F103VC Dragon개발보드 소개
2.1 Features
3. Examples
3.1 GPIO Output without SDK
3.2 GPIO Output with SDK
3.3 GPIO Output with BitBand
3.4 GPIO Input - Polling
3.5 GPIO Input - Interrupt
3.6 General Purpose Timer
3.7 Systick - Delay
3.8 Systick - Interrupt
3.9 USART - Polling
3.10 USART - Interrupt
3.11 USART - Name Card
3.12 Interrupt Priority1
3.13 Interrupt Priority2
3.14 Power Management - Sleep
3.15 Power Management - Stop
3.16 Power Management - StandBy
3.17 Mode Privilege
3.18 USART Monitor Program