ARM Architecture
* Update history
- 2012.9.11 : 초기 Release
7. ARM Instruction Sets
7.1 Understanding ARM Instruction set
7.2 ARM Instruction sets
7.3 Data Processing Instructions
7.4 Multiply Instructions
7.5 Load/Store Instructions
7.6 Load/Store Multiple Instructions
7.7 Branch Instructions
7.8 Status Register Access Instructions
7.9 Software Interrupt Instruction
7.10 SWP Instruction
7.11 Conditional Execution
8. Thumb Instruction Sets
8.1 Thumb Instruction 특징
8.2 Thumb Instruction 제약 사항
8.3 Thumb, ARM Instruction 비교
8.4 ARM/Thumb Interworking
9. AAPCS
9.1 Procedure Call Standard for the ARM Architecture
9.2 Function Parameter Passing
7. ARM Instruction Sets
7.1 Understanding ARM Instruction set
ARM Instruction Set은 ARM 명령어들 즉 어셈블리어를 이야기 하는 것입니다. 대부분은 C 코드를 이용해서 작업을 합니다만, 어셈블리어도 어느정도는 숙지하고 있어야 하는 몇가지 이유가 있습니다.
(1) ARM 어셈블리어를 잘 파악하고 있으면 ARM의 구조를 더 잘 이해할 수 있습니다.
(2) 전통적인 ARM의 Startup 코드는 스택이 초기와 되기 전에는 C로 작성을 할 수가 없습니다. 최근 Cortex 계열은 Reset 벡터의 초기 번지가 Stackaddress여서 C코드 만으로도 부트로더 작성이 가능 합니다.
(3) C컴파일러의 최적화가 아주 잘 되어 있지만, 사람이 주의해서 작성하는 어셈블리 코드보다는 최적화 할 수 없습니다.
(4) Debugging in detail (instruction level debugging)
일반적인 ARM 어셈블리어 형식 입니다.
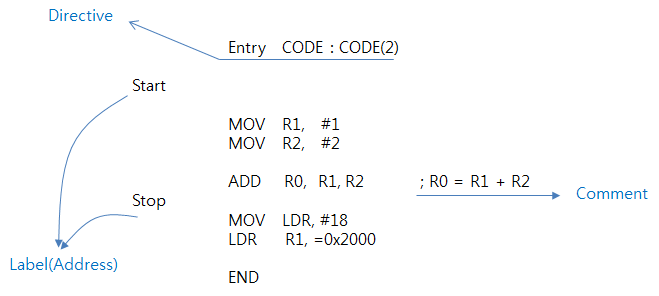
- Directive : 어셈블리 코드의 특성을 지정하는 지시어 입니다.
- Label : 반드시 Space없이 첫 번째 컬럼에 위치해야 하고, Label 자체가 Address가 됩니다.
- Comment : 주석은 ";" 문자 이후로 작성을 하면 됩니다.
- Instructions(ADD, MOV, LDR ...) : 명령어들은 반드시 앞 부분에 적어도 하나 이상의 Space가 있어야 합니다.
7.2 ARM Instruction sets
ARM Processor는 2가지 명령어 세트를 지원하는데 32bit ARM 명령어와 16bit Thumb 명령어가 있습니다. Thumb 명령어는 모든 ARM 프로세서에서 지원하는 것은 아니고 Thumb 특성을 지원하는 Core에서만 사용이 가능 합니다. 최근 Cortex 계열에서는 16bit, 32bit 명령어를 같이 사용할 수 있는 Thumb-2 Instruction도 지원 합니다. 심지어 Cortex-M3의 경우에는 Thumb-2 Instruction만 사용이 가능 합니다. 8bit 길이의 Jave Byte Code도 사용 할 수 있는데 이것도 Thumb 명령어와 같이 모든 ARM Processor가 지원하는 것은 아닙니다.
| Instruction Type | Instructions |
| Data Processing | ADD, ADC, SUB, SBC, RSB, AND, ORR, BIC, MOV, CMP, TEQ, … |
| Multiply | MUL, MULS, MLA, SMULL, UMLAL, … |
| Load/Store | LDR, LDRB, LDRH, LDRSH, LDM, STR, STRB, STRH, STRSH, STM, … |
| Branch | B, BL, BX, BLX, … |
| Status Access | MRS, MSR |
| Swap | SWP, SWPB |
| Coprocessor | MRC, MCR, LDC, STC |
7.3 Data Processing Instructions
(1) Instructions

< Cond >
해당 명령의 조건 실행 플래그입니다. 해당 플래그를 통해 명령을 CPSR의 플래그 상태에 따라 선택적으로 실행을 할 수 있습니다. ARM에서 지원하는 굉장히 강력한 기능으로 조건부 실행을 잘 이용하면 분기문을 최대한 줄여 시스템 성능을 향상 시킬 수 있습니다.
< I >
Operland 2로 지정되어 있는 부분이 Immediate Operand 인지 아닌지 여부를 나타내는 비트 입니다. 즉 25번필드[I] 가 "0" 이면 [11 : 0] 가 shifter operand로 동작을 하고 "1" 이면 Immediate Operand로 동작 합니다. Immediate Operand라 함은, 예를 들어 MOV R0, #0x01234 라고 했을 경우 #0x1234를 가리키는 말입니다.
< Opcode >
데이터 프로세싱 명령 중 어떤 명령인지를 나타내는 필드 입니다. 해당 필드와 명령어는 다음과 같습니다.
| Opcode | Mnemonic | Meaning | Action |
| 0000 | AND | Logical AND | Rd = Rn AND shifter_operand |
| 0001 | EOR | Logical Exclusive OR | Rd = Rn EOR shifter_operand |
| 0010 | SUB | Subtract | Rd = Rn - shifter_operand |
| 0011 | RSB | Reverse subtract | Rd = shifter_operand - Rn |
| 0100 | ADD | Add | Rd = Rn + shifter_operand |
| 0101 | ADC | Add with carry | Rd = Rn + shifter_operand + Carry |
| 0110 | SBC | Subract with carry | Rd = Rn – shifter_operand – NOT(Carry) |
| 0111 | RSC | Reverse Subract with carry | Rd = shifter_operand - Rn – NOT(Carry) |
| 1000 | TST | Test | Update flags after Rn AND shifer_opernad |
| 1001 | TEQ | Test Equivalence | Update flags after Rn EOR shifer_opernad |
| 1010 | CMP | Compare | Update flags after Rn - shifer_opernad |
| 1011 | CMN | Commom | Update flags after Rn + shifer_opernad |
| 1100 | ORR | Logical OR | Rd = Rn OR shifter_operand |
| 1101 | MOV | Move | Rd = shifter_operand |
| 1110 | BIC | Bit clear | Rd = Rn AND NOT(shifter_operand) |
| 1111 | MVN | Move Not | Rd = NOT(shifter_operand) |
< S >
S 비트가 1인 경우는 데이터 프로세싱 명령의 결과가 CPSR에 영향(Rd의 레지스터가 PC인 경우 SPSR의 값으로 CPSR을 복원)을 미칩니다.
즉, 0인 경우에는 CPSR은 변하지 않습니다.
< Rn >
ARM 데이터 프로세싱 명령은 그 결과와 첫 번째 오퍼랜드는 항상 레지스터로 지정해야 합니다. Rn은 첫 번째 오퍼랜드를 가리키는 것으로 위에서 Op1으로 표기한 것에 해당합니다. ARM에서 한번에 볼 수 있는 범용 레지스터는 sp, lr, pc 등을 포함해서 r0~r15 까지입니다. 즉, 4Bit를 통해 레지스터를 나타내게 됩니다. 해당 필드는 명령에 따라 사용되지 않기도 합니다. MOV나 MVN등이 이에 해당합니다.
< Rd >
오퍼레이션의 결과가 저장될 레지스터를 의미합니다. 역시 레지스터를 가리키므로 4Bit를 사용하고 모든 명령에서 디폴트로 사용되는 필드. ARM의 데이터 프로세싱 명령의 결과는 항상 레지스터로 들어갑니다.
< Operand 2 >
Immediate Operand 혹은 레지스터 Operand 입니다. <I> 필드가 0일 경우 레지스터 입니다.
(2) Syntax : <operation>{cond}{s} Rd, Rn, operand2
- Operand2 is a register
ADD R0, R1, R2
- Operand2 is immediate value
BIC R1, R2, #0xFF
- Operand2 shifted value
ADD R0, R1, R2, LSL #2
SUB R0, R1, R2, LSR R3
- Data movement
MOV R0, R1
MOV R0, #0x1
- Comparisons set flags only
CMP R0, R1
CMP R2, #0x01
(3) Immediate value

Immediate value(상수 값)= ROR immed_8 by 2*rot
MOV R0, #0xFF000000
MOV R0, #0x12
MOV R0, #0x104 ; 100000100 --> permitted
MOV R0, #0x102 ; 100000010 --> not permitted
MOV R0, #0x12345678 ; 10010001101000101011001111000--> not permitted
위의 예제에서 상수 값으로 "#0x104" 는 사용할 수 있는데 "#0x102", "#0x12345678" 값으로 올수 없는 이유는 무엇 일까요?
"ROR immed_8 by 2*rot" 의 수식을 잘 살펴 보시기 바랍니다. 어렵다구요 ? ^^ 네. 쉬운 계산이 아닐 수 있습니다.
우선 "#0x12345678" 값은 쉽게 판단이 될것 같은데요. Rotate없이 표현 가능한 값의 범위가 8bit 를 넘었습니다.
"#0x102" 는 왜 안될가요 ? 쉽게 생각하면 8-bit immediate 값을 #rot 값을 2배 한만큼 오른쪽으로 로테이션을(ROR) 해서 Immediate value을 만들 수 있는 값을 반드시 상수로 사용해야 한다는 말입니다. 역시 말로는 잘 설명이 되지 않네요. 아래 그림들을 참조 하시기 바랍니다.


아래 Immediate value의 또 다른 예제 입니다.
MOV r0, #0xfc000003 ; 11111100000000000000000000000011
r0에 상수 값 0xfc000003을 넣는 명령입니다. 해당 값은 8Bit 값 0xFF를 32Bit로 확장하고 오른쪽으로 6번 Rotate 시킨 값입니다. 그래서 에러가 나지 않습니다.
(4) 32-bit Instruction format
MOV R0, #1
굉장히 단순한 예제 인데요. 위에서 배운 32-bit Instructions 포맷을 분석해 보도록 하겠습니다. 코드를 Disassebly 해보면
"0xE3A00001(1110 001 1101 0 0000 0000 0000 00000001)" 입니다.

Instruction 포맷을 다시한번 살펴 보면 아래와 같습니다.
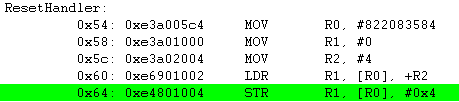
[31:28] : 1110 - 7.11 Conditional Execution 에서 배울 예정 입니다. 우선은 그냥 "1110" 은 Always execution flag 라고 알아 두시기 바랍니다.
[27:25] : 001 - Operland 2로 지정되어 있는 부분이 Immediate Operand이므로 25번 비트가 "1" 입니다.
[24:21] : 1101 - Opcode "MOV" 는 "1101" 입니다.
[20] : 0 - 명령어 Opcode에 "S" 가 붙지 않았으므로 CPSR에 영향을 미치는 명령어는 아닙니다.
[19:16] : 0000 - Rn 부분으로 레지스터 번호를 표현 합니다. 만약 "MOV R2, #1" 였다면 Rn 이 "0000" 이 아니라 "0010" 일 것입니다.
[15:12] : 0000 - Rd 부분이 없으므로 "0000" 입니다.
[11:0] : 8bit Immediate value 로서 "#1" 에 해당하는 "00000001" 입니다.
* 참고
MOV R2, #1 명령에 대한 32-bit Instruction 포맷 = 0xE3A02001(1110 001 1101 0 0000 0010 0000 00000001)
(5) Examples
R0 = 0x00
R1 = 0x22
R2 = 0x02
R3 = 0x00
R4 = 0x00
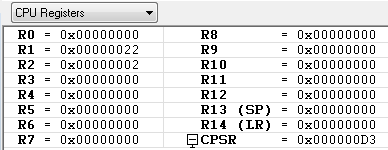
레지스터의 값들이 위와 같을때 아래 예제들을 차례대로 수행 했을때의 각각의 레지스터 값은 ?
AND R0, R0, #0xFF ; 0x00 & 0xff = R0의 값은 변환 없음
ADD R0, R0, #1 ; R0 = R0 + 1 = 0x1
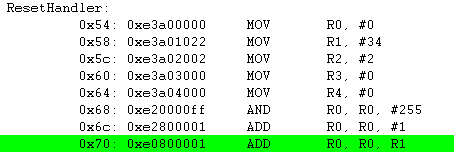
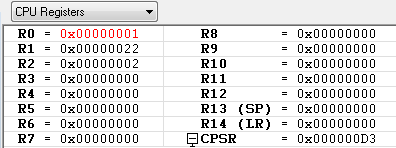
ADD R0, R0, R1 ; R0 = R0 + R1 = 0x01 + 0x22 = 0x23
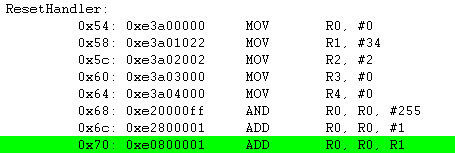
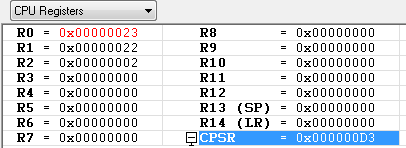
LSL R1, R0, #2 ; 0x23(100011) LSL #2 = 0x8C(10001100) -> 참고로 왼쪽으로 2번 쉬프트 하면 *4 를 한것과 같습니다.
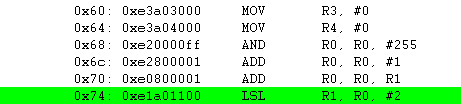
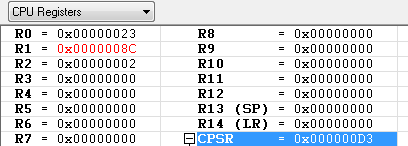
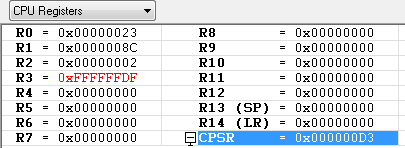
SUB R3, R2, R1, LSR R2
R3의 값이 0xFFFFFFDF 로 복잡한 값이 나왔습니다. 왜 이런 결과가 나왔을까요 ?
우선 R1을 오른쪽으로 2번 쉬프트 시키면 0x23이 되고 R2(0x02) 에서 R1(0x23) 을 빼면 결과값이 -0x21가 되고 이 값을 2의 보수로 표시하면
0xFFFFFFDF 가 됩니다.
0x21 = 00000000000000000000000000100001
-0x21 = 11111111111111111111111111011111 --> 0x21의 2의 보수
참고로 2의 보수를 취하는 방법은 원래의 2진수에서 0->1, 1->0 으로 바꾼후에 1을 더하면 되겠지요.

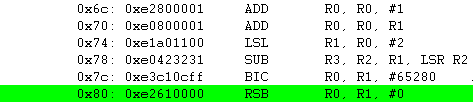
BIC R0, R1, #0xFF00
R1(0x8C) = 0000000010001100
0xFF00(65280) = 1111111100000000
BIC = 0000000010001100 ; 0xFF00 로 Bit clear를 해도 R1의 값은 변화가 없네요.
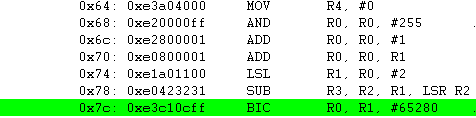
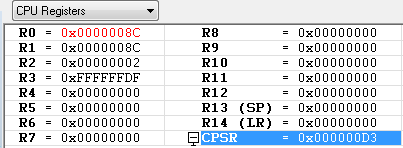
RSB R0, R1, #0 ; #0 - R1(0x8C) = 0xFFFFFF74(0x8C 의 2의 보수 값)
RSB 명령어는 SUB와는 반대로 마이너스 연산을 수행 합니다.
7.4 Multiply Instructions
(1) Multiply (Accumulate) Syntax
MUL{<cond>}{S} Rd, Rm, Rs ; Rd = Rm * Rs
MUA{<cond>}{S} Rd, Rm, Rs, Rn ; Rd = (Rm * Rs) + Rn
(2) Examples
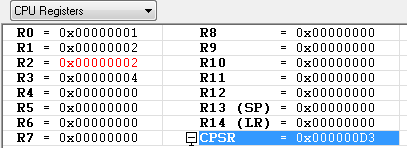
R0 = 0x01
R1 = 0x02
R2 = 0x03
R3 = 0x04
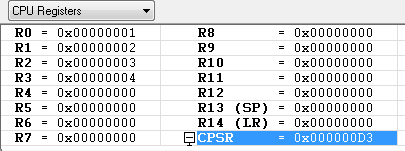
레지스터의 값들이 위와 같을때 아래 예제들을 차례대로 수행 했을때의 각각의 레지스터 값은 ?
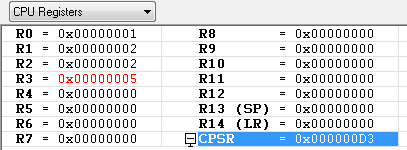
MUL R2, R0, R1 ; R2 = R0*R1 = 0x02
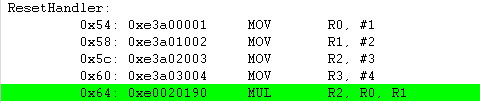
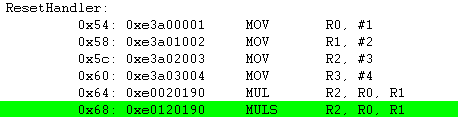
MULS R2, R0, R1 ; R2 = R0*R1 = 0x02
MUL 명령과 같은 명령입니다. 하지만 MUL뒤에 "S" 가 붙으면 명령어 처리가 끝난 이후에 CPSR의 Flag Field 가 연산 결과에 따라서 업데이트가 됩니다.
자세한 사항은 7.11 Conditional Execution 에서 자세히 다루도록 하겠습니다.
MLA R3, R2, R1, R0 ; R3 = R2*R1 + R0
참 효율적이네요. 명령어 하나로 곱하기 연산과 더하기 연산을 같이 할 수 있습니다.
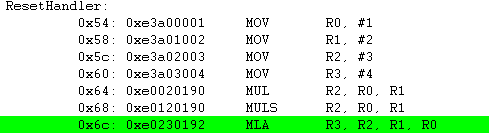
SMULL R3, R2, R1, R0 ; R3,R2 = R1*R0
부호있는 64비트 곱셈 명령어 입니다. R1*R0 하여 상위 32비트는 R2에 하위 32비트는 R3에 저장 합니다.
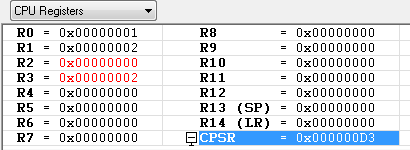
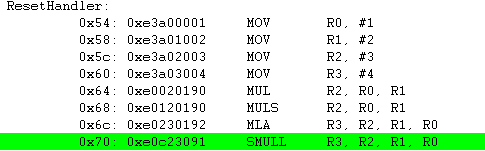
위에서 부호있는 연산이 나왔는데, 좀더 복잡한 예제를 풀어 보도록 하겠습니다.
R0 = 0xF0000002
R1 = 0x02
R2 = 0x00
R3 = 0x00
초기 레지스터의 값이 위와 같을때 SMULL 연산 이후의 R2, R3 의 값은 어떻게 될까요 ?
우선 0xF0000002가 음수 이기 때문에 연산을 하기 위해서는 2의 보수값(F0000002의 2의 보수 = 0xFFFFFFE)을 먼저 취합니다. 그리고 나서 0xFFFFFFE * 0x02 = 0x1FFFFFFC 를 합니다. 연산이 끝나고 나서 음수를 표현하기 위해서 다시 0x1FFFFFFC 의 2의 보수를 취합니다. 이때 SMULL이 64비트 곱셈 명령어 이므로 64비트로 확장 합니다. 이렇게 하면 상위 32비트는 0xFFFFFFFF 이고 하위 32비트는 0x04가 됩니다.
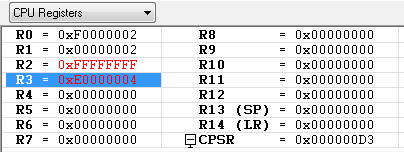
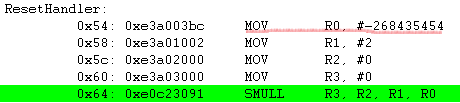
위의 그림에서 "MOV R0, #-268435454" 라고 R0를 초기화 하고 있습니다. 이것은 0xf0000002의 값이 음수(최상위 비트가 1이면 음수이죠)이기 때문에 컴파일러에서 알기 쉽도록 음수 10진수로 표현을 해준것 입니다.
7.5 Load/Store Instructions
Memory의 내용을 레지스터로 이동(Load)하거나 레지스터의 내용을 메모리에 저장(Store) 하는 명령어 입니다. 데이터 Access단위에 따라서 아래와 같이 분류 됩니다. Load, Store는 ARM 명령어 가운데 가장 많이 사용되는 명령어 이며 굉장히 중요합니다. 반드시 숙지 하고 있어야 합니다.
- Word : LDR, STR
- Byte : LDRB, STRB
- Halfword : LDRH, STRH
- Signed byte : LDRSB
- Signed halfword : LDRSH
(1) Syntax
LDR{cond}{size} Rd, <address>
STR{cond}{size} Rd, <address>
(2) Addressing Mode
- Pre Index : Rd 레지스터에 데이터를 먼저 이동시킨 후 <address> offset을 증가 혹은 감소 합니다.
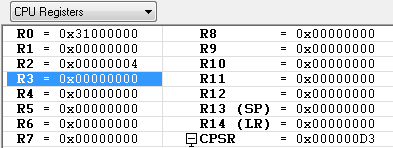
R0 = 0x31000000
R1 = 0x00
R2 = 0x00
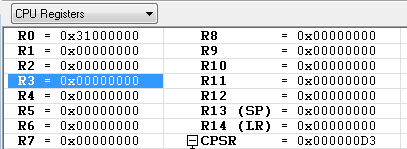
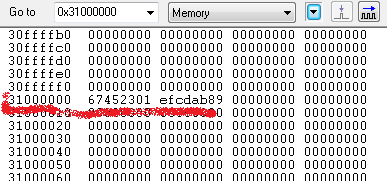
레지스터의 값들과 메모리(메모리 배열은 리틀 엔디언) 값이 위와 같을때 아래 예제들을 차례대로 수행 했을때의 각각의 레지스터와 메모리의 값은 ?
LDR R1, [R0] ; R1 <-- M[R0]
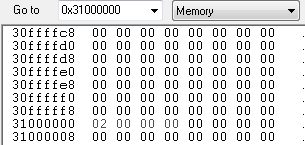
R0가 가르키고 있는 0x31000000 번지의 메모리 값은 0x67452301 입니다. 그러므로 LDR 연산 이후에 R1에는 0x67452301 값이 저장 됩니다.
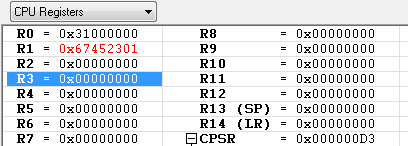

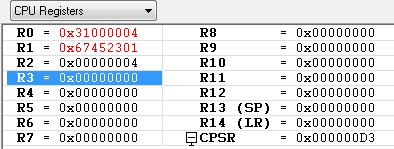
STR R1, [R0, #4] ; R1 <-- M[R0+4]
R0가 가르키는 0x31000000 번지에서 4-byte 를 더한 번지의 메모리 위치에 R1(0x67452301) 값을 저장 합니다.
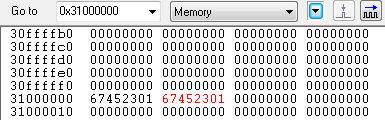
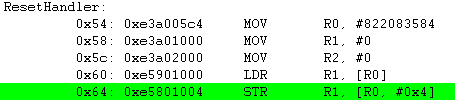
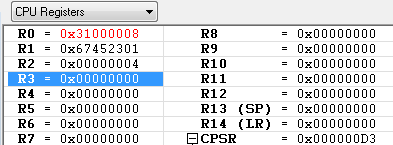
STR R1, [R0, #4]! ; R1 <-- M[R0+4], then R0 <-- R0+4
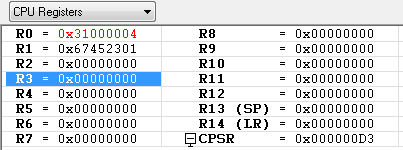
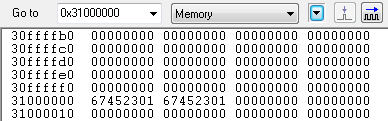
R1에 0x31000004번지의 메모리 내용 0x67452301을 저장하고 난 이후에 R0의 레지스터값 + 0x04 를 수행 합니다.
예제에서 0x30000000, 0x30000004 번지의 내용이 동일해서 혼동 뒬수도 있지만 R1에는 R0레지스터값 + 0x04 = 0x30000004 번지의 값이 저장이 된다는 것을 기억 하시기 바랍니다.
- Post Index: Offset calculation after data transfer
R0 = 0x31000000
R1 = 0x00
R2 = 0x04
레지스터의 값들과 메모리(메모리 배열은 리틀 엔디언) 값이 위와 같을때 아래 예제들을 차례대로 수행 했을때의 각각의 레지스터와 메모리의 값은 ?
LDR R1, [R0], R2 ; R1 <-- M[R0], then R0 <-- R0+R2
R1에 R0 가 가르키는 0x31000000번지의 메모리값 0x67452301의 값을 저장하고 나서 R0 = R0(0x31000000) + R2(0x04) 가 됩니다.
Preindex 방식에서는 R0를 먼저 계산하고 나서 메모리 번지의 값을 R1에 저장하였으나 Postindex 방식에서는 순서가 반대가 됩니다.

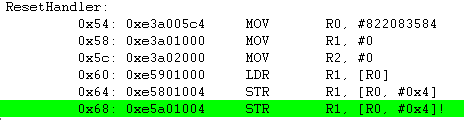
STR R1, [R0], #4 ; R1 <-- M[R0], then R0 <-- R0+4
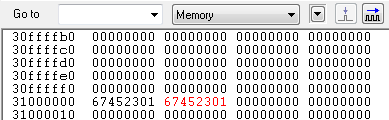
레지스터 R1의 값 0x67452301을 메모리 0x31000004 번지에 저장을 하고난 이후에 R0 = R0(0x310000004) + 0x04 를 수행 합니다.
(3) Literal Pool
32bit의 모든 값을 가질 수 없고 12bit를 가지고 일정 형식에 맞추어서 사용해야 합니다. Immediate value 에서 자세히 설명 했던 내용입니다.
MOV R0, #0x12345678 ; illegal (build error)
LDR R0, =0x12345678 ; legal (build success)
MOV R0, #0x104 ; legal
MOV R0, #0x102 ; illegal
위의 예제에서 0x12345678 값을 LDR 명령어를 사용하면 제약 없이 사용이 가능한 것을 알수 있습니다. LDR명령어를 사용하는 것이 편해보이기는 하지만 메모리에 접근하기 때문에 속도는 많이 느려지겠지요..
7.6 Load/Store Multiple Instructions
LDR, STR 명령어와 기능은 동일 하지만 Rn레지스터 값이 가르키는 메모리 위치애 여러개 레지스터 값들을 저장 할 수 있습니다.
(1) Syntax
LDM{cond}{addr_mode} Rn{!}, <register_list>{^}
STM{cond}{addr_mode} Rn{!}, <register_list>{^}
(2) Addressing Mode
- IA : increment after
- IB : increment before
- DA : decrement after
- DB : decrement before
(3) Examples
* 레지스터 값들
R0 = 0x000A
R4 = 0x000B
R5 = 0x000C
R13 = 0xFFF0
STMIA R13!, {R0,R4-R5} 연산의 결과는 ?

STMIB R13!, {R0,R4-R5} 연산의 결과는 ?

STMDA R13!, {R0,R4-R5} 연산의 결과는 ?

STMDB R13!, {R0,R4-R5} 연산의 결과는 ?

참고로 ARM Compiler는 Stack 동작시 Full Descending Stack 방식으로 동작 하고 있습니다. STMDA 명령어와 동일한 방식 입니다. 즉 Stack Pointer는 항상 유효한 데이터를 가르키고 있고 주소가 감소하는 방향으로 저장이 됩니다.
- Stack 에서 PUSH, STMDB 대신에 아래와 같이 사용이 가능 합니다.
STMFD SP!, {R4-R12, LR}
- Stack 에서 POP, LDMIA 대신에 아래와 같이 사용이 가능 합니다.
LDMFD SP!, {R4-R12, PC}
LDMFD SP!, {R0-R12, PC}^
"^" 연산자는 목적지의 레지스터(Rd)가 PC인 경우에 SPSR을 CPSR로 북구까지 하라는 명령 입니다.
7.7 Branch Instructions
혹시 서브 함수와 서브 프로시져의 차이점을 알고 있나요 ? 2가지 모두 메인 프로그램 흐름에서 벗어(분기하여)나 특정 작업을 수행하는 것은 동일 합니다. 하지만 엄밀하게 차이점을 이야기 하면 서브 프로시져는 분기 이후에 분기하기 이전의 흐름으로 되돌아 오지 않고 분기한 주소에서 부터 프로그램 수행이 계속 될 경우에 사용을 하고 서브 함수는 분기한 주소에서 특정 작업을 수행하다가 분기 이전의 주소로 복귀하여 프로그램을 수행 하도록 합니다. 설명이 길어 졌네요. 그림을 통해서 차이점을 구분해 보도록 합시다.
* 서브 프로시져 호출시 프로그램 흐름

* 서브 함수 호출시 프로그램 흐름

(1) Syntax
B{L}{cond} <target_addr>
target_addr <-- pc + SignExtended(immed_24)<<2
- 여기서 PC는 Pipeline 에서 설명 했드시 Branch Instruction 의 주소에서 8을 더한 위치가 됩니다.
(2) Branch Range
-32MB ~ +32MB
분기 범위가 +- 32MB 까지로 제한이 되는 이유는 2^24 = 16MB << 2 를 하면 64MB 이고 이를 +- 로 하면 32MB 까지가 되는 것입니다.
(3) Examples
B Label
MOV PC, #0
MOV PC, LR
레제스터 R15(PC) 에 직접 분기할 주소를 저장하여도 분기가 가능 합니다.
LDR PC, =func
참고로 LDR 명령어를 사용하면 Branch명령어를 사용했을때보다 1가지 잇점이 있는데 4GB이내에서는 어디든지 분기가 가능 하다는 것입니다.
Branch 명령어의 분기 range는 -32MB ~ +32MB의 제약이 있습니다.
물론 메모리에서 주소를 읽어와야 하므로 성능면에서는 좋지 않겠지요.
(5) 함수 호출(BL)
- 함수 호출시
BL func
--> B 명령어와 다른점은 LR레지스터에 PC-4 의 Address값이 H/W적으로 저장이 됩니다.
- ARM 모드 함수 종료시
MOV PC, LR --> LR 에는 이미 BL 명령어의 주소 +4 의 값이 저장이 되어 있어 BL 명령어 다음부터 명령을 수행할 수 있도록 합니다.
- Thumb 모드 함수 종료시
BX LR
(6) Subsequent Function Calls
함수안에서 함수를 다시 호출을 하면 어떤일이 발생을 할가요. 예제 코드를 가지고 분석해 보도록 하겠습니다.

위의 예제에서 서브함수를 호출하고난 이후에 main 루틴에 있는 R2에는 #3이 저장이 되어 있어야 합니다. 언뜻 보기에 #11이 저장이 되어 있을것 같습니다.
R0, R1은 func1에서 각각 #3, #4 가 저장이 되고 func2를 거치면서 #5, #6이 저장이 됩니다. 그래서 #11이 될것이라고 예상이 될수 있지만 사실은 func1의 ADD 명령어만 반복해서 실행이 될것입니다. 왜냐하면 main에서 func1으로 branch할때까지는 LR에는 BL명령어 Address+4 가 저장이 되고 func1에서 func2로 분기 할때 다시 LR에는 func2로 분기하는 BL명령어 Address+4가 저장이 되어 최종 func2에서 MOV PC, LR 을 실행을 하면 func1의 ADD 명령어로 PC가 이동을 하고 다시 func1에서 MOV PC, LR 이 실행이 되면 LR 값에 의해서 다시 func1의 ADD 명령어가 반복해서 실행이 될것입니다. 조금 복잡한듯 하지만 잘 따라가 보면 알 수 있습니다. 이 예제에서 알수 있는것은 서브 함수를 호출할 경우에는 서브함수내에서 반드시 LR과 서브함수에서 사용할 레지스터들을 Stack에 백업을 하고 서브함수에서 복귀전에 다시 Stack에서 복원을 해야 한다는 것을 알 수 있습니다. 그러면 위의 예제를 main 루틴에 있는 R2에 #3이 저장이 되도록 수정을 하면 어떻게 될까요 ?
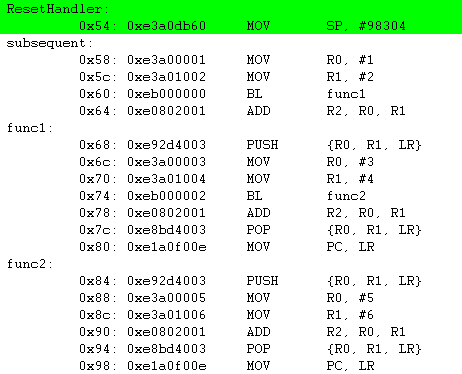
위의 그림에서 MOV SP, #98304 를 하는 이유는 Stack을 사용하기 위해서 Supervisor 모드의 Stack 포인터를 초기화 하는 것입니다. 참고로 Stack 포인터의 주소는 실제 타겟마다 다를 수 있습니다. Stack 포인터는 주로 시스템의 주 메모리에 위치 합니다.
(7) Veneer
베니어라는 용어가 나오네요. 혹시 베니어 합판 이라는 말을 들어 보셨나요? 작은 나무 조각들을 겹겹이 붙여서 만든 합판 입니다. 여기 나오는 Veneer라는 개념이 흡사 베니어 합판을 만드는것과 유사한것 같습니다. 사실 Veneer라는 것은 ARM의 특성은 아니고 컴파일러에서 지원하는 기능 입니다.원래 B, BL 등의 분기 명령어는 -32MB ~ 32MB 범위내에서 분기가 가능하다고 하였습니다. 하지만 아래 그림과 같이 MyFunc2을 호출할때 컴파일러에서 자동으로 Veneer라는 중간 분기점을 만들어서 32MB 범위를 벗어나도 서브 함수를 호출 가능하도록 만들어 줍니다.
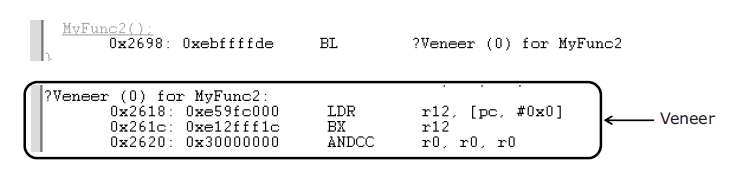
위의 기능 이외에도 추가로 아래와 같은 기능이 있습니다.
- ARM to ARM or Thumb to Thumb 으로 분기
: Long branch capability
- ARM to Thumb or Thumb to ARM 으로 분기
: Long branch capability and interworking capability
7.8 Status Register Access Instructions
(1) Syntax
MRS{cond} Rd, CPSR ; CPSR의 값을 Rd 레지스터로 읽어 옵니다.
MRS{cond} Rd, SPSR ; SPSR의 값을 Rd 레지스터로 읽어 옵니다.
MSR{cond} CPSR_<fields>, #<immediate>
MSR{cond} CPSR_<fields>, <Rm> ; Rm 레지스터의 값을 CPSR에 저장 합니다.
MSR{cond} SPSR_<fields>, #<immediate>
MSR{cond} SPSR_<fields>, <Rm> ; Rm 레지스터의 값을 SPSR에 저장 합니다.
이전에도 설명 했지만 CPSR 레지스터의 구조를 다시한번 확인 바랍니다.
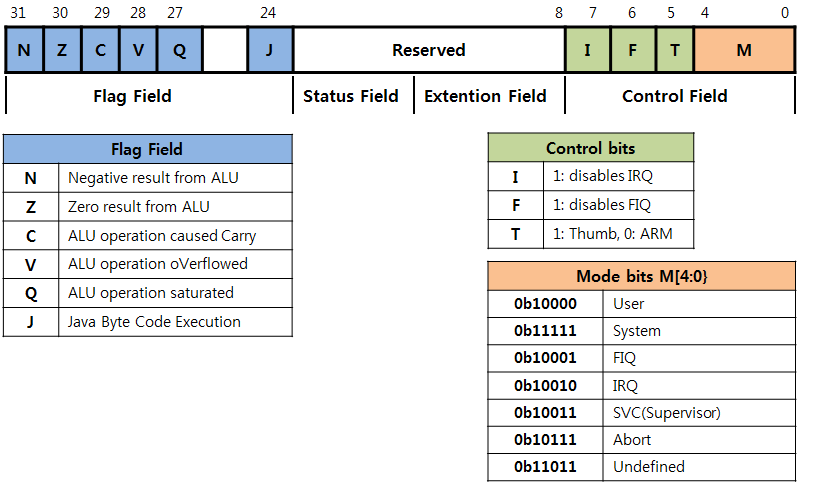
(2) Examples
- IRQ 를 Enable 하는 코드 입니다.
아래 명령어 들이 수행되는 동안의 CPSR레지스터의 변화값을 확인해 보시기 바랍니다.
MRS R0, CPSR
BIC R0, R0, #0x80 ; 7번 비트를 clear 하면 인터럽트가 활성화 됩니다.
MSR CPSR, R0
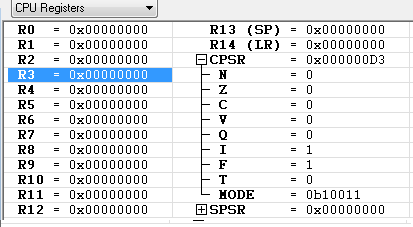

BIC, MSR 명령에 의해서 CPSR의 I 가 "0" 으로 변경(Unmask) 되어 Interrupt가 가능하게 되었습니다. 참고로 CPSR_fc 와 CPSR은 같은 레지스터 입니다.
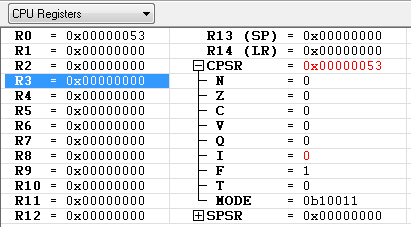
- IRQ 를 Disable 하는 코드 입니다.
MRS R0, CPSR
ORR R0, R0, #0x80 ; 7번 비트를 set 하면 인터럽트를 사용할 수 없습니다.
MSR CPSR, R0
간혹 MSR_c, MRS_x 등으로 사용되는 예제들이 있는데 밑줄 다음에 오는 flag의 의미는 아래와 같습니다. 그리고 밑줄 다음의 _c, _x 등은 의미를 명확하게 하기 위해서 사용하는 것일뿐 생략해도 아무 문제가 되지는 않습니다.
c = PSR[7:0]
x = PSR[15:8]
s = PSR[23:16]
F = PSR[31:24]
7.9 Software Interrupt Instruction
(1) Syntax
SWI{cond} <immed_24>
SEI 명령어는 S/W 적으로 강제적으로 ARM에 IRQ 예외를 발생 시킵니다. 주로 OS에서 User application들이 운영체제 서비스 루틴을 호출할 경우에 특권모드에서 콜하기 위해서 많이 사용됩니다.
(2) Examples
SWI #0x123456
7.10 SWP Instruction
(1) Syntax
SWP{cond}{B} Rd, Rm, [Rn]
(2) Operation
Temp <-- [Rn]
[Rn] <-- Rm
Rd <-- Temp
(3) Semaphore Instruction
명령어 수행중에 인터럽트없이 메모리의 Read, Write 를 할 수 있는 Atomic 동작을 할수 있습니다. Atmoic이라는 용어가 나오는데요, 이것은 어떤 동작을 1개의 오퍼레이션으로 완료하는 것을 의미합니다. 즉 Atmoic 오퍼레이션이 수행되는 동안에는 인터럽트가 발생하지 않는 것입니다.
(4) Examples
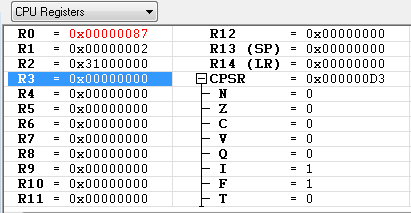
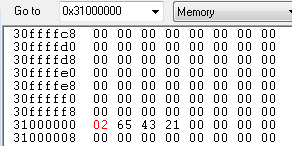
R0 = 0x01
R1 = 0x02
R2 = 0x31000000
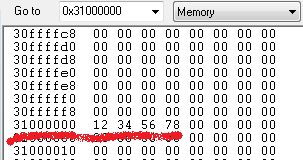
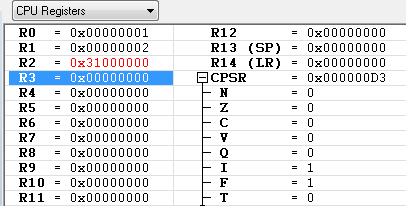
레지스터의 값들이 위와 같을때 아래 예제들을 차례대로 수행 했을때의 각각의 레지스터 값은 ?
SWP R0, R1, [R2]
R2 가 가르키는 주소(0x31000000)의 값 0x78563412의 값이 R0에 저장이 되었고,
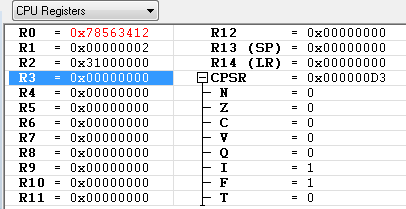
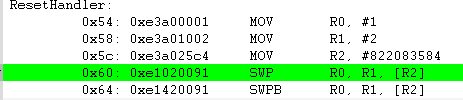
R1의 값 0x02가 R2가 가르키는 0x31000000 메모리에 저장이 되었습니다.
아래의 예는 바이트 명령어 입니다. SWPB 명령어를 사용했을 경우 R0 에는 어떤 값이 저장이 될까요 ?
SWPB R0, R1, [R2]

동작은 SWP와 동일하고 단지 바이트 단위로 SWP가 된다는 것만 다릅니다. 위의 그림들을 참조 하시기 바랍니다.
7.11 Conditional Execution
ARM모드 에서 굉장이 강력한 기능으로 명령어들을 특정 조건이 만족했을 때에만 실행 시킬 수 있습니다. 이렇게 조건부 실행이 가능하면 성능면에서 아래와 같은 잇점이 있습니다.
- Increase code density
- Decrease the number of branches
Thumb모드에서는 분기명령어 이외에는 이 조건부 실행 기능을 사용할 수 없습니다. 그 이유는 명령어의 길이가 Thumb 모드에서는 16bit로 제한이 되어서 조건부 실행을 할만큼 레지스터 공간이 충분하지 못하기 때문입니다. 그러면 실행 가능한 조건이라는 것은 어떤것들이 있을까요?
ARM 명령어 설명할때 맨처음에 나왔던 그림인데요아래 그림을 보고 실행 조건에 대해서 설명하도록 하겠습니다.
< Cond >
해당 명령의 조건 실행 플래그입니다. 데이터 프로세싱 명령어에도 당연히 포함됩니다.
해당 플래그를 통해 명령을 현재 플래그 레지스터(CPSR)의 상태에 따라 실행 여부를 결정하는데 사용되는 플래그입니다.
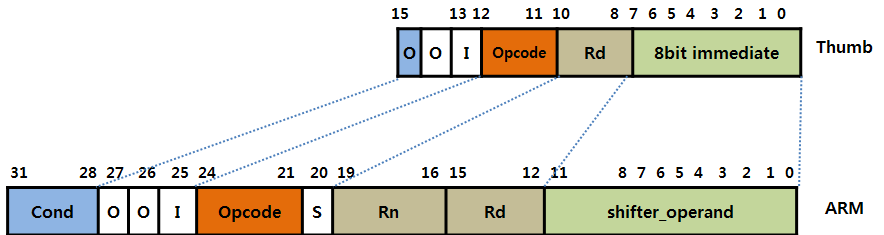
ARM 명령어의 길이는 32bit라고 하였습니다. 32bit중에서 4bit를 조건부 실행을 하는데 할당하고 있습니다. [31:28] bit가 바로 <Cond> 비트 입니다.
그리고 <Cond> 필드에 올수 있는 것들은 아래 표와 같습니다.
| Cond | Mnemonic | Meaning | Condition flag state |
| 0000 | EQ | Equal | Z = 1 |
| 0001 | NE | Not Equal | Z = 0 |
| 0010 | CS/HS | Carry set / unsigned >= | C = 1 |
| 0011 | CC/LO | Carry clear / unsigned < | C = 0 |
| 0100 | MI | Minus/Negative | N = 1 |
| 0101 | PL | Plus/Positive or Zero | N = 0 |
| 0110 | VS | Overflow | O = 1 |
| 0111 | VC | No overflow | O = 0 |
| 1000 | HI | Unsigned higher | C = 1 & Z = 0 |
| 1001 | LS | Unsigned lower or same | C = 0 | Z = 1 |
| 1010 | GE | Signed >= | N == V |
| 1011 | LT | Signed < | N != V |
| 1100 | GT | Signed > | Z == 0, N == V |
| 1101 | LE | Signed <= | Z == 1 or N! = V |
| 1110 | AL | Always | |
| 1111 | (NV) | Unpredictable |
참고로 우리가 지금까지 사용해 왔던 MOV, ADD 명령어 뒤에 Mnemonic 없이 사용을 하면 "Always" 가 적용되어서 실행이 된 것입니다.
(1) Condition Flag Change
Condition Flag변경은 Data Processing Instructions 에 의해서만 영향을 받으면 명령어 뒤에 "S" Prefix를 사용해야만 합니다.
Condition Flag는 CPSR레지스터의 [31:24] 비트 필드에 정의 되어 있습니다.
설명이 조금 복잡한가요. 예제를 통해서 살펴 보도록 합시다.
(1) Examples1
NZCV 플래그가 변화하는 예제 들입니다. 여기서 N(Negative), Z(Zero result) 까지는 명확한것 같은데 Carry, Overflower 는 어떻게 다른 것일 까요 ?
아래 예제들을 수행하면서 차이점을 비교해 보시기 바랍니다.
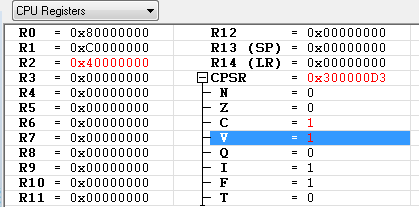

- N : 연산의 결과 R2(0x40000000)의 최상위 비트가 "1" 이 아님
- Z : 연산의 결과 R2가 0x0 이 아님
- C : 32-bit 를 넘어 섰으므로 Carry 가 발생
- V : ARM 에서 Overflow 를 검출하는 방식은 MSB 이전 비트에서 발생한 Carry("0" 과 "1" 을 더해도 Carry가 발생하지 않았으므로 "0")와 MSB에서 발생한 Carry("1" 과 "1" 을 더해서 Carry 가 발생 했으므로 "1")의 값이 달라지는 경우에 Overflow가 검출 됩니다.
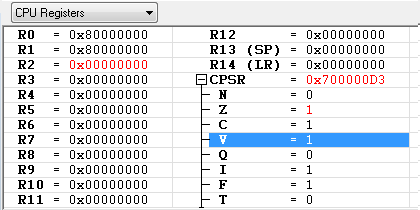

- N : 연산의 결과 R2(0x00000000)의 최상위 비트가 "0" 이므로 Negative 발생하지 않음
- Z : 연산의 결과 R2가 0x0 이므로 세팅
- C : 32-bit 를 넘어 섰으므로 Carry 가 발생
- V : MSB 이전 비트에서 발생한 Carry("0" 과 "0" 을 더해도 Carry가 발생하지 않았으므로 "0")와 MSB에서 발생한 Carry("1" 과 "1" 을 더해서 Carry 가 발생 했으므로 "1")의 값이 달라지는 경우에 Overflow가 검출 됩니다.
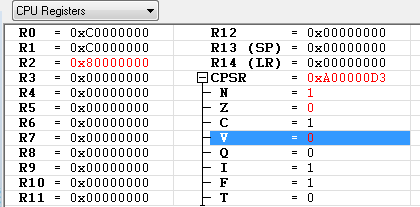

- N : 연산의 결과 R2(0x80000000)의 최상위 비트가 "1" 이므로 Negative 발생
- Z : 연산의 결과 R2가 0x0 이 아님
- C : 32-bit 를 넘어 섰으므로 Carry 가 발생
- V : MSB 이전 비트에서 발생한 Carry("1" 과 "1" 을 더해서 Carry가 발생했으므로 "1")와 MSB에서 발생한 Carry("1" 과 "1" 을 더해서 Carry 가 발생 했으므로 "1")의 값이 다르지 않으므로Overflow가 검출 되지 않습니다.
(2) Examples2
ADD R0, R1, R2 --> does not update the flags( "S" Prefix 가 없음 )
ADDS R0, R1, R2 --> update the flags ( "S" Prefix 가 있음 )
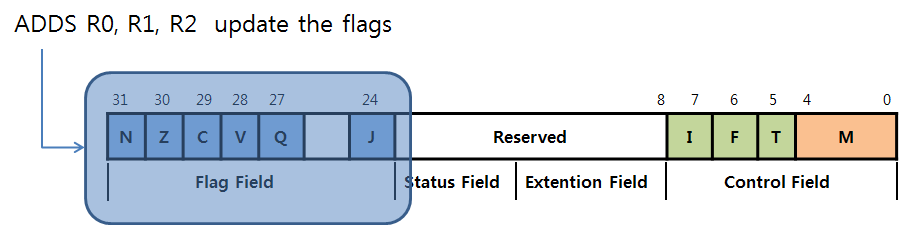
SUBS R2, R1, R0 -- SUBS 명령 실행 이후에 CPSR의 condition flag가 업데이트 됩니다.
ADDEQ R3, R1, R0 -- condition field 에 Z flag 가 Set 되어 있으면 실행이 되고 그렇지 않으면 NOP(단순히 CPU의 1Clock을 소비)명령이 실행 됩니다.
condition field 에 Z flag 가 Set 되었다는 의미는 R1, R0 의 값이 같아서 R3에 "0" 이 저장이 되었다는 의미 입니다.
참고로 CMP, TST, CMN, TEQ instructions 등의 비교, 검사 명령어 들은 "S" Prefix 가 없이도 CPSR의 condition flag 가 업데이트 입니다.
다음 구문을 Conditional Execution을 사용했을 경우와 안했을 경우로 구분해서 비교해 보세요.
if(a==0) a = a + 1;
else a = a – 1;
| Non Conditional Execution | Conditional Execution |
|
cmp r0, #0 bne AAA add r0, r0, #1 b BBB AAA sub r0, r0, #1 BBB |
cmp r0, #0 addeq r0, r0, #1 subne r0, r0, #1 |
5 instructions 1 branch execution |
3 instructions 0 branch execution |
조건부 명령을 사용함으로서 instructions 을 2개나 줄였고 가장 중요한 것은 branch 명령없이 구현을 했다는 것입니다.
branch 명령은 ARM pipeline을 무너뜨리기 때문에 성능에서 굉장히 치명적입니다.
8. Thumb Instruction Sets
Thumb 명령어는 ARM 명령어에 비해서 16bit라는 명령어의 길이 때문에 많은 제약이 있습니다. 가장 단점은 조건부 실행 명령을 사용할 수가 없다는 것입니다.
Thumb 명령어는 ARM을 이해하는 있어서 큰 부분을 차지하지는 않다고 생각 되기 때문에 간단하게 특성 정도만 확인하고 넘어 가도록 하겠습니다.
8.1 Thumb Instruction 특징
(1) 16-bit length instruction set
(2) ARM 명령어보다 코드의 집적도가 높습니다.( about 65% of ARM instruction )
(3) 일반적으로는 32bit ARM명령어 보다는 속도가 느리지만 16bit memory 시스템에서는 그렇지 않을 수도 있습니다.
8.2 Thumb Instruction 제약 사항
- Limited Access to Registers : R0-R7 registers are accessible.
- Narrow Range of Immediate Value
- Not Flexible for Exception Mode
- Exception Handler should be executed in ARM mode. : Exception이 발생하면 항상 ARM 모드로 전환이 됩니다.
- Limited conditional instruction.
- Branch instructions can be executed conditionally.
- Inline Barrel Shifter is not used.
8.3 Thumb, ARM Instruction 비교
아래 코드를 ARM 명령어와 Thumb 명령어로 작성하고 비교해 보시기 바랍니다.
if(x>=0) return x;
else return –x;
| ARM Instruction | Thumb Instruction |
| abs_rtn CMP r0, #0 RSBLT r0, r0, #0 MOV pc, lr |
abs_rtn CMP r0, #0 BGE return NEG r0 r0 return MOV pc, lr |
| - Instructions : 3 - Size : 12Bytes - 16-bit bus : 6access - 32-bit bus : 3access |
- Instructions : 4 - Size : 8Bytes - 16-bit bus : 4access - 32-bit bus : 4access |
위의 표에서 16-bit bus 일경우의 access 횟수를 보면 오히려 Thumb 명령어가 효율을 보이기도 합니다.
8.4 ARM/Thumb Interworking
ARM 모드와 Thumb 모드를 같이 사용 할 수가 있습니다. 하지만 동시에 명령어 들을 섞어서 사용할 수 있는것은 아니고 ARM 모드에서 BX branch명령어에 의해서 Thumb 모드로 전환을 할수가 있고 다시 Thumb 모드에서 BX 명령어를 이용해서 ARM 모드로 복귀 할 수 있습니다.
(1) BX Instruction
BX{cond} Rm
CPSR.T <-- Rm[0], PC <-- Rm & 0xFFFFFFFE
BX명령어는 일반 분기명령어와 비슷한것 같지만 조금 다릅니다. 이유는 32bit ARM 모드에서 Thumb 모드로 전환을 할때 32bit 명령어 에서 16bit 로 변경되면서 PC의 주소 증가하는 값이 4byte에서 2byte로 바뀌기 때문에 그런 것입니다. 당연히 Thumb 모드에서 ARM 모드로 다시 복귀 할때는 반대의 경우 이겠죠? 조금 어렵죠 ? 예를 들어서 설명 하도록 하겠습니다.
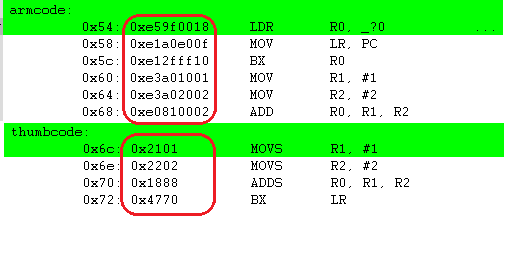
위의 그림에서 붉은 박스를 잘 보시면 armcode 부분은 32비트 코드 사이즈이고, thumbcode 부분은 16비트 길이의 코드 사이즈임을 알 수 있습니다.
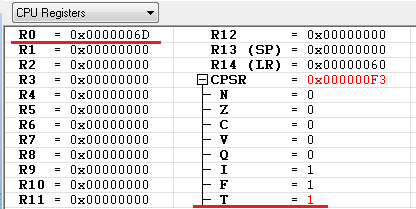
0x5C address의 코드 BX, R0 코드가 수행이 되었을때 레지스터의 상태를 보면 아래와 같습니다.
thumbcode 가 시작되는 주소는 0x6C 인데, armcode의 "BX, R0(0x6d)" 코드에 의해서 0x6C가 아닌 0x6D 로 분기 하라고 되어 있습니다. 올바르게 수행이 될까요 ? 물론 잘 수행이 됩니다. 이것의 비밀은 위에서 설명한 "CPSR.T <-- Rm[0], PC <-- Rm & 0xFFFFFFFE" 에 있습니다.
우선 CPSR.T = 1 로 변경이 되는 것은 Rm(1101101) 의 최하위 비트가 "1" 이기 때문입니다. 또한 Rm(1101101) & 0xFFFFFFFE 에 의해서 실제 BX분기 명령어에 의해서 분기되는 주소는 0x6C 가 됩니다. BX 명령어에서 Rm(1101101) & 0xFFFFFFFE 해서 분기를 하는 이유는 ARM 모드(32비트)이건 Thumbmode(16비트) 이건 PC의 주소를 항상 2의 배수를 유지 하기 위해서 입니다.
9. AAPCS
9.1 Procedure Call Standard for the ARM Architecture
쉽게 이야기 하면 ARM에서 서브 루틴을 호출할때의 레지스터, 스택 사용 방법에 대한 것입니다. 아래 표는 Procedure call시 사용되는 레지스터들을 표로 정리한 것입니다.
| Register | Synonym | Special | Role in ther procedure call standard |
| r15 | PC | Program Count | |
| r14 | LR | Link Register | |
| r13 | SP | Stack Pointer | |
| r12 | IP | The Intra-procedure-call scratch register | |
| r11 | v8 | Variable register8 | |
| r10 | v7 | Variable register7 | |
| r9 | v6 | Variable register6 Platform register Ther meaning of the register is defined by the platform standad |
|
| r8 | v5 | Variable register5 | |
| r7 | v4 | Variable register4 | |
| r6 | v3 | Variable register3 | |
| r5 | v2 | Variable register2 | |
| r4 | v1 | Variable register1 | |
| r3 | a4 | Argument / scratch register4 | |
| r2 | a3 | Argument / scratch register3 | |
| r1 | a2 | Argument / scratch register2 | |
| r0 | a1 | Argument / result / scratch register1 |
* 참고로 scratch register들은 서브루틴 호출시 변경이 있을 수 있는 위험이 있는 레지스터 입니다. 그러므로 서브루틴 호출시 Stack에 백업한 이후 서브루틴을 호출 해야 합니다.
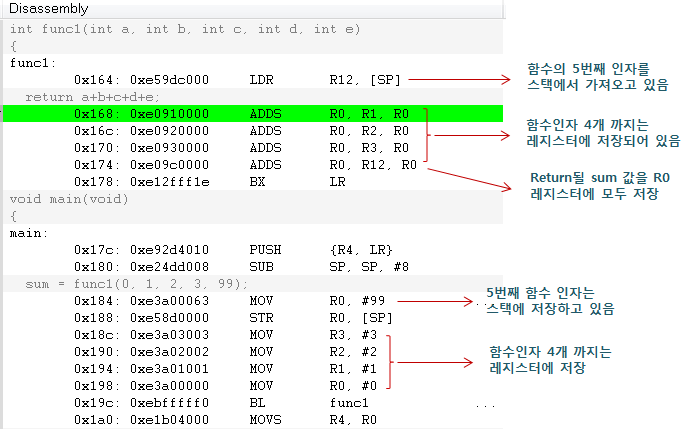
위의 표에서 알수 있는 것은 함수를 호출할때 함수의 인자 4개 까지는 r0 ~ r3에 저장이 되어 호출이 되고 함수 에서 return에 의한 결과 값은 r0에 담아서 함수를 호출한 메인 함수로 값을 전달하고 있음을 알수 있습니다. 그럼 함수의 인자가 4개 이상인 경우에는 어떻게 되는 것일까요? 5번째 인자 부터는 Stack에 저장한후 함수 에서 POP해서 사용합니다. Stack은 메인 메모리를 사용하므로 가능하면 함수 인자는 4개 까지만 사용하는 것이 성능 향상에 도움이 됩니다.
9.2 Function Parameter Passing
void main(void)
{
int sum;
// R0 레지스터에 a+b+c+d+e 의 합이 저장되어 return이 됩니다.
sum = func1(0, 1, 2, 3, 99);
}
int a --> R0
int b --> R1
int c --> R2
int d --> R3
int e --> Stack
Return Value --> R0
int func1(int a, int b, int c, int d, int e)
{
return a+b+c+d+e;
}
위의 C 코드를 Disassembly 해보면 다음과 같습니다. 오른쪽 설명을 참조 하시기 바랍니다.