ARM Architecture
* Update history
- 2012.7.5 : 초기 Release
- 2012.9.26 : 일부 블럭 다이어그램들 이미지 교체 및 Pipeline 부분 보충 설명 추가
1. 임베디스 시스템 소개
1.1 Embedded System 이란
1.2 Embedded System 구성
1.3 Operating System
2. Processor
2.1 CPU
2.2 RISC and CISC
2.3 General Register
2.4 SFR(Special Function Register)
2.5 ALU (Arithmetic Logic Unit)
2.6 Control Unit
2.7 Bus
2.8 Processor 기본 동작
2.9 Pipeline
3. 프로세서 성능
3.1 CPU 성능 증가 기법들
3.2 CPU Clock 증가의 한계점
3.3 Multi Core Processor
4. Embedded Software
4.1 Machine & Language
4.2 컴파일러
4.3 어셈블러
4.4 Linker
1. 임베디스 시스템 소개
1.1 Embedded System 이란
ARM프로세서는 예전에는 주로 경량화된 임베디드 시스템에서 사용되었는데, 최근에는 엄청난 성능으로 무장하여 마이크로소프트사 에서도 ARM을 지원하는 등 좀더 복잡한 사용자 UI가 필요한 분야(주로 스마트 기기)에 까지 그 쓰임세가 확대 되었습니다.
Embedded System의 특징을 몇가지로 요약하면 다음과 같습니다.
- 장치에 내장된 Process에 의해 특정한 목적의 기능을 수행하는 하드웨어와 소프트웨어가 조합된 경량화된 시스템
- 입출력 장치를 내장하고 있다.
- Processor 동작은 주로 S/W에 의지해 동작 한다.
- 자동차, 네트워크 장비, Mobile 단말기, 정보가전 등에 응용되고 있다.
- 저전력, 안정성, 저렴함
1.2 Embedded System 구성
임베디드 시스템은 크게 Hardware와 Software로 구성되어 집니다.
(1) Hardware
- CPU(Processor)
- Memory 장치 : ROM(NOR), RAM(SDRAM, SRAM), Storage(NAND, SD) ...
- I/O 장치 : Network, LCD, GPIO ...
메모리 중에서 NOR, SDRAM등은 Random access가 가능하나 NAND 메모리이 경우는 Randam access가 불가능 하고 CPU입장에서 Address를 가지고 접근을 할 수 가 없다. 그래서 NAND의 경우에는 메모리라고 하기 보다는 저장장치에 가깝습니다. Address를 가지고 Random access가 가능 하다면 XIP(Execute In Place) 가 가능하여 부팅을 위한 메모리로서 사용이 가능합니다. 최근에는 NAND메모리만 있어도 부팅이 가능한 디바이스들(S3C6410, S5PV210 등)이 있으나 이것은 NAND메모리에서 직접 실행되는 것이 아니라 CPU 레벨에서 NAND 메모리의 0번 블럭의 내용을 CPU의 Internal SRAM에 로드 시켜서 NAND메모리에서 부팅이 가능한것처럼 보여지는 입니다. 그래서 CPU의 OM(Operation Mode)등의 포트를 잘 보면 NAND 메모리의 동작 Cycle, Size 등을 H/W 적으로 정해 주는 부분이 있습니다.
(2) Software
- System Software : Firmware(OS 개념이 없음), Device Driver(OS 관점)
- RTOS, Embedded OS
- Middleware : Network Stack Protocol, File System ...
- Applications
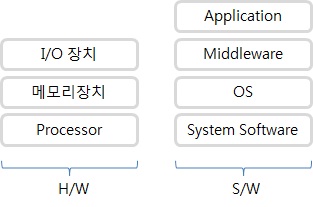
위의 그림에서 System Software는 Device Driver혹은 HAL(Hardware Abstraction Layer, 하드웨어 추상화 계층)이라고도 부릅니다.
1.3 Operating System
(1) RTOS (Real-Time OS)
- 주어진 임의의 작업에 대해 정해진 시간 내에 수행할 수 있도록 하는 환경을 제공
- 개발시에 주로 운영체제와 Task들이 같이 빌드 됩니다.
- VxWorks, uC/OS, FreeRTOS, pSOS(삼성), Nucleus
RTOS에 대해서는 여러가지 정의가 많이 있지만 예를 들어보면 좀 감이 올것 같습니다. 일반적으로 우리가 사용하는 PC의 경우에 우리가 Excel 등을 실행 시켰을 경우 조금 늦게 실행이 된다고 해서 큰 일이 발생 하지는 않습니다. 실행이 될때까지 조금 기다리면 되겠죠. 하지만 무인자동차를 운행하는 시스템등에서 전방에 장애물이 나타났을 경우 반드시 부딪히기전에 멈춰서거나 피해가야 되겠지요. 어떤 상황(부딪히는 상황)에 대해서 정해진 시간(부딪히기 전)까지는 반드시 응답을 주어야 하는 시스템에서 RTOS등이 필요하게 됩니다.
(2) Embedded OS
- 여러 복잡한 작업들을 동시에 효율적으로 수행하기 위한 환경 제공
- 이미 동작 중에 있는 운영체제 상에서 새로운 프로세스를 이식 할 수 있다. --> RTOS에 비해서 Application 개발을 편리하게 할수 있습니다.
- Windows CE, Linux, Android, iOS
Embedded OS는 최근에 스마트폰, 네비게이션 등에 많이 이용되고 있습니다.
2. Processor
2.1 CPU
(1) CPU (Central Processing Unit)
CPU의 구성은 Processor Core + System Bus + Peripherals (H/W IP) + Memory 로 이루어 집니다. 이렇게 CPU안에 주변장치(Peripherals), Memory등을 모두 담고 있는 시스템을 SOC (System-On-Chip) 라고 한다. 아래 그림은 SOC의 한 예이다. 우리가 앞으로 공부하려고 하는 ARM도 바로 Processor Core 중의 한 종류 입니다. Data 버스와 Instruction 버스가 따로 있는 것으로 보아서 하바드 아키텍쳐 구조 입니다.
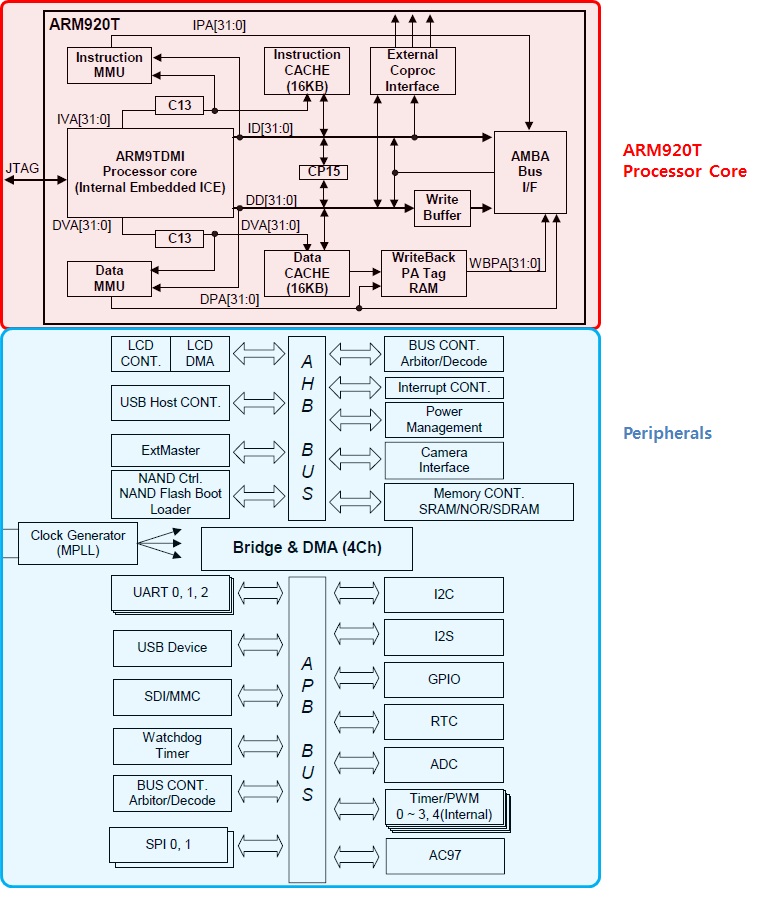
(2) Processor Core
- 메모리 장치로 부터 프로그램의 구성 요소인 명령어들을 fetch, decoding,
execution 하는 동작을 합니다.
- 레지스터(Register), 연산장치(ALU), 제어장치(Control Unit), 버스(Bus), Cache memory(Optional), MMU(Optional) 등으로 구성 됩니다.
- Processor Core의 종류에는 ARM, MIPS, Intel의 Sandy Bridge 등도 Processor Core의 한 종류 입니다.
2.2 RISC and CISC
(1) RISC (Reduced Instruction Set Computer)
RISC의 대표 주자는 ARM, MIPS, SunSPARC, IBM PowerPC 등이 있습니다. ARM사의 다음 버젼에서는 64비트를 지원한다고 합니다.
- Same Length for all instruction, big code sizes
단순한 ADD명령이나 복잡한 명령이나 모두 32bit의 동일한 명령어 길이를 가지고 있기 때문에 코드의 집적도가 떨어질 수 밖에 없습니다. 이를 보완하기 위해서 16bit 코드 사이즈를 가지고 Thumb 명령어를 지원하고 있고 Cortex-M 계열에서는 ARM, Thumb명령어의 장점을 취한 Thumb2 명령어를 사용하고 있습니다.
- Simple Hardware, Low Power, Mobile Device 들을 위해서 최적화 되어 있음.
명령어의 길이가 모두 같기 때문에 코드 집적도는 떨어지지만 이 덕분에 H/W 가 단순해지고 전력 소모를 줄일수 있습니다.
- Load Store Architecture, needs many registers
명령어의 개수가 많지 않기 때문에 그에 따라서 레지스터가 좀더 필요하게 되었습니다.
(2)
CISC (Complex Instruction Set Computer)
CISC 대표주자는 Intel x86, Alpha 계열이 있습니다.
- Complex Hardware
명령어의 길이가 기능에 따라서 다르기 때문에 복잡한 H/W 처리가 요구 됩니다.
- Different Length for different instructions, low code size
수행하는 명령에 따라서 명령어의 사이즈가 다르게 설계 되어 단순한 일을하는 명령어는 코드의 사이즈가 작고 복잡한 일을 수행하는 명령어는 사이크가 큽니다. 이로 인해서 코드 사이즈는 작아 졌으나 각기 다른 사이즈의 명령어를 수행하기 위한 H/W 설계가 복잡해 지고 상대적으로 RISC에 비해 전력 소모가 많아졌습니다.
- Need small register
복잡한 작업을 수행하는 다양한 명령어 들이 있기 때문에 RISC에 비해서 많은 레지스터가 필요 하지는 않습니다.
2.3 General Register
프로세서 코어에 위치하고 있고 프로세서가 접근 가능한 가장 빠른 임시 기억 장치로 ARM 프로세서는 아래과 같은 3가지 종류의 레지스터가 있습니다.
(1) General Purpose Register : 프로그램 데이터 처리에 사용됩니다.
(2) Control Register : Stack Pointer, Link Register, Program Counter
- Stack Pointer는 현재 프로세스 모드의 Stack의 Top 주소를 가르키고 있습니다.
- Link Register는 서브루틴 분기시 서르부틴을 끝마치고 복귀 할 주소를 가지고 있습니다.
- Program Count는 현재 실행 중인 주소 값입니다.
(3)Program Status Register : Processor 의 상태정보와 ALU의 결과 정보를 저장하고 있습니다.
2.4 SFR(Special Function Register)
참고로 일반 레지스터 외에 특별한 레지스터가 있는데 주로 Processor 주위에 있는 주변 장치들을 제어하기 위해서 SFR (Special Function Register) 가 있습니다. 주로 Memory-Mapped 방식으로 접근이 되고 대부분 bit 단위로 제어가 됩니다.(AND, OR, EOR ... ) 그리고 Memory-Mapped 되어 있다는 말은 SFR은 각 레지스터에 해당하는 주소가 정해져 있어 주소를 통해서 접근이 가능 하다는 이야기 입니다. S/W 엔지니어가 ARM 펌웨어 프로그램을 한다고 하면 대부분의 작업이 바로 SFR 레지스터를 세팅하고 제어하는 일입니다.
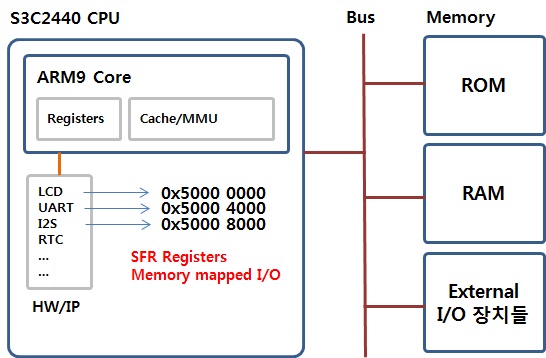
예제로 아래 그림은 ARM9 프로세서중의 하나인 삼성의 S3C2440의 UART제어를 위한 SFR 레지스터 입니다.
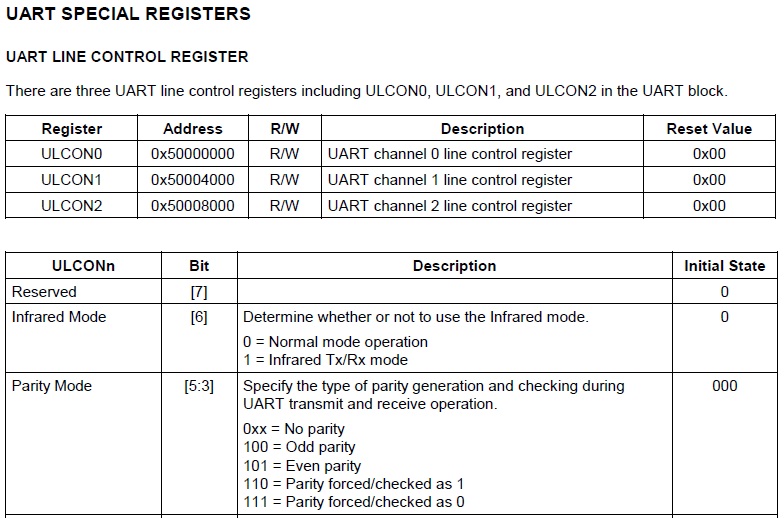
ULCON0 레지스터의 경우 0x50000000 번지를 통해서 접근이 가능합니다. 0x50000000 번지의 32Bit 레지스터는 각 비트별로 기능이 나누어져 있습니다. 0 ~ 1 비트는 UART 통신시 WordLength 를 설정할 수 있고, 레지스터별로 각 비트의 기능이 세분화 되어 있습니다.
S3C2440 CPU에서 UART 관련 SFR을 세팅하는 코드를 예를 들면 다음과 같습니다.
// S3C2440 CPU의 UART SFR 레지스터의 주소를 정의 합니다.
#define rULCON0 (*(volatile unsigned *)0x50000000) //UART 0 Line control
#define rUCON0 (*(volatile unsigned *)0x50000004) //UART 0 Control
#define rUFCON0 (*(volatile unsigned *)0x50000008) //UART 0 FIFO control
#define rUMCON0 (*(volatile unsigned *)0x5000000c) //UART 0 Modem control
#define rUTRSTAT0 (*(volatile unsigned *)0x50000010) //UART 0 Tx/Rx status
#define rUERSTAT0 (*(volatile unsigned *)0x50000014) //UART 0 Rx error status
#define rUFSTAT0 (*(volatile unsigned *)0x50000018) //UART 0 FIFO status
#define rUMSTAT0 (*(volatile unsigned *)0x5000001c) //UART 0 Modem status
#define rUBRDIV0 (*(volatile unsigned *)0x50000028) //UART 0 Baud rate divisor
// 정의된 SFR 레티스터의 주소에 직접 값을 써 넣을 수 있습니다.
rUFCON0 = 0x0; //UART channel 0 FIFO control register, FIFO disable
rUFCON1 = 0x0; //UART channel 1 FIFO control register, FIFO disable
rUFCON2 = 0x0; //UART channel 2 FIFO control register, FIFO disable
rUMCON0 = 0x0; //UART chaneel 0 MODEM control register, AFC disable
rUMCON1 = 0x0; //UART chaneel 1 MODEM control register, AFC disable
//UART0
rULCON0 = 0x3; //Line control register : Normal,No parity,1 stop,8 bits
2.5 ALU (Arithmetic Logic Unit)
(1) 산술 연산 수행 : ADD, SUB 등 연산 수행
(2) 논리 연산 수행 : AND, OR, XOR 등 연산 수행
(3) Program Status Register Update : Negative, Zero, Carry, Overflow, Saturation(Sticky Overflow, ARM5TE 구조만 있음)
Program Status Register Update 기능은 조건부 명령과 관련이 있습니다. 조건부 명령에 관해서는 ARM Instruction 에서 자세히 설명 하도록 하겠습니다.
2.6 Control Unit
(1) 메모리에서 명령을 인출 합니다.
(2) 인출된 명령을 분석하여 어떤 명령인지 어떤 레지스터들이 사용되는지를 확인 합니다.
(3) 명령어 실행에 필요한 제어신호를 만들어 내고 실행 합니다.
2.7 Bus
(1) CPU와 메모리 사이의 데이터 통로
(2) CPU : Bus Master, Memory : Bus Slave
(3) Bus는 Address 버스와 Data 버스가 있습니다.
2.7.1 Von-Neumann Bus
CPU와 메모리 사이에 물리적으로 하나의 버스만 존재 합니다.
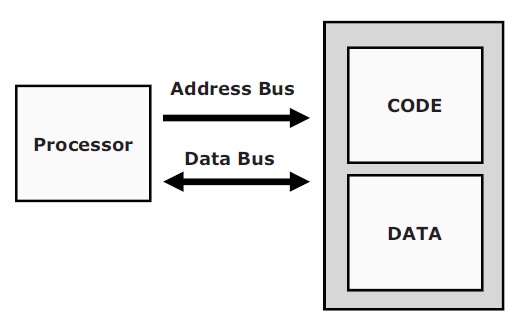
2.7.2 Harvard-Architecture Bus
CPU와 메모리 사이에 물리적으로 2개 이상의 Bus 존재하여
Von-Neumann Bus 구조에 비해서 CODE, DATA 에 동시에 접근 할 수 있습니다.
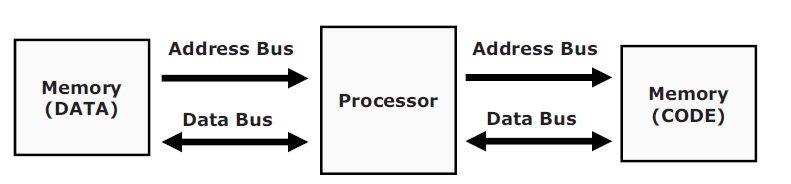
2.8 Processor 기본 동작
(1) 명령어 인출( Instruction Fetch )
명령어를 캐시 혹은 메모리에서 읽어 명령어 파이프 라인에 저장
(2) 명령어 해독( Instruction Decoding )
어떤 일을 하는 명령어 인지, 어떤 레지스터를 사용하는지 해독
(3) 명령어 실행( Instruction Execution )
ALU 연산수행 - 메모리 접근 명령어인 경우 메모리 접근을 위한 주소 계산
(4) 메모리 접근( Memory Access )
- ALU 연산에 의해 결정된 주소를 사용하여 메모리 접근
- 메모리 접근 명령어가 아닌경우, 결과를 한 사이클 동안 저장
(5) 레지스터 쓰기( Register Write Back )
- ALU 연산결과를 Regisger 에 기록
- 메모리에서 읽은 값을 Register 에 기록
2.9 Pipeline
- Cache와 더불어 프로세서의 속도를 획기적으로 개선 하였습니다.
- 하나의 명령어를 여러 개의 독립적인 작업들로 나누어 병렬적으로 실행 합니다.
ARM7의 경우 3단 파이프 라인을 가지고 있는데, 아래 4개의 명령어가 처리되는 과정을 파이프 라인이 있을 경우와 없을 경우로 나누어서 설명하도록 하겠습니다.
JOB1 : MOV R0, #0x1
JOB2 : MOV R1, #0x2
JOB3 : ADD R2, R0, R1
JOB4 : MOV R3, R2
* 파이프 라인이 없는 시스템
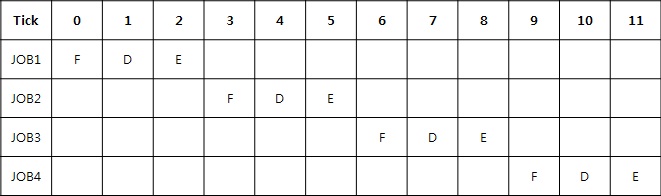
파이프 라인이 없는 시스템에서는 4개의 명령어를 수행하는 각 단계별로 3Cycle씩 총 12Cycle을 소모하고 있습니다.
* 3단 파이프 라인 시스템( ARM7 )
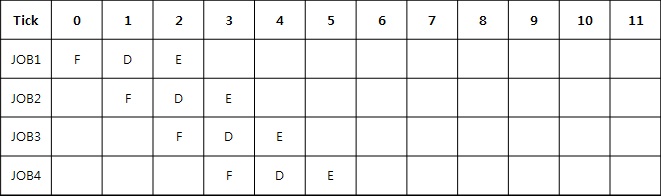
3단 파이프 라인이 있는 시스템에서는 4개의 명령어를 수행하는 처음 단계에만 3Cycle을 소모하고 다음 부터는 1Cycle이 소모되어 총 6Cycle을 소모하고 있다. 결과적으로 파이프 라인이 없는 시스템 보다 2배 정도의 성능 향상을 가져 옵니다.
- F(Instruction Fetch), D(Instruction Decoding), E(Instruction Execution)
- 위의 예는 모든 명령어가 캐시에 있어서(그러므로 모든 과정이 1Cycle 이내에 처리) 메인 메모리 접근이 없다는 가정 하에서 수행되는 결과 입니다. 만약 프로세서가 주메모리에 접근해야 하는 일이 발생한다면 추가로 메모리 접근 파이프라인 단계가 필요 하게 됩니다
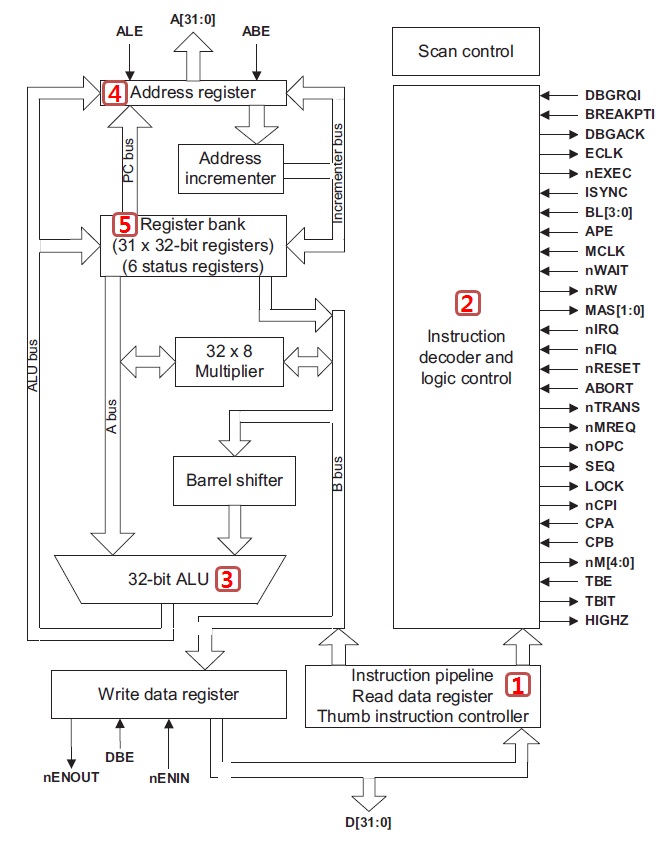
지금까지 설명한 프로세서의 기본 동작을 위의 그림(ARM7TDMI Processor Block Diagram)으로 설명을 하면, [1] 메모리에서 명령어를 Fetch하여 Instruction Pipeline에 집어 넣고 [2] 그 명령어를 Control unit 에서 해독하고 [3]ALU에서 실행, [4]메모리 접근 명령의 경우 메모리 접근할 주소 계산, [5] 그리고 결과를 다시 Register에 Write 하고 있습니다. [2] 에서 Instruction Decoder는 명령어를 읽어서 해석하는 일을 하며, 이에 대하여 Control Unit은 각종 제어 신호를 발생하게 됩니다. 예를 들어 ALU에게 더하기를 하라는 신호를 발생 시킨다던가, 또는 메모리에게 특정 주소를 Read할 수 있도록 신호를 발생시킨다든가 하는 여러 가지 Control signal들 입니다.
3. 프로세서 성능
3.1 CPU 성능 증가 기법들
(1) Clock
CPU 성능을 높이는데 가장 일반적인 방법으로 단순히 CPU의 동작 클럭을 높이는 방법이 있습니다. 당연히 같은 작업을 할때 CPU Tick 시간이 빠른 CPU가 그렇지 않은 CPU보다 빠르게 동작을 하겠지요.
(2)
Execution Optimization
아래 내용들은 간단히 개념 정도만 설명하도록 하겠습니다. 각 항목 하나에 대한 이론만 하더라도 분량이 상당할것 같습니다.
- Pipeline : 기본 개념은 하나의 명령어를 여러개의 독립된 작업으로 나누어 병렬적으로 실행. Pipeline은 이전에도 한번 설명 하였습니다.
- Branch prediction(분기예측) : 정상적인 프로그램 흐름에서 분기를 하게되면 Pipeline이 무너지게 되는데 이렇게 되면 다시 Pipeline에 명령어가 적재되어 실행이 되기까지 CPU는 Stall 하게 됩니다. 이를 방지하기 위해서 프로세서가 분기문을 실행하기도 전에 분기 지점을 예측하여 Pipeline을 다시 적재하는 기능 입니다. 물론 분기가 되는 지점을 프로세서에서 100% 예측할수는 없습니다. 예측이 맞으면 좋은거고(Pipeline이 무너지지 않음), 틀렸을 경우에는 원상태로 복구하는 추가 작업이 펄요 합니다. 분기 예측에는 동적예측, 정적 예측 등 여러가지 방법이 있습니다.
- Out-of-order execution
Address: Instructions
0x0004 : a = b + c
0x0008 : d = a + b
0x000c : z = x + y
위의 예제에서 보통 프로세서는
0x0004 번지부터 순차적으로 0x0008, 0x000c 번지로 실행이 되는데, 자세히 보면 0x0008번지는 "a", "b" 와 연관이 있기 때문에 0x0004번지가 반드시 먼저 실행이 완료가 될때까지 기다린 이후에 실행이 되어야 합니다. CPU입장에서 보면 일을 하지 못하는 유휴한 시간이 되겠지요. 하지만 0x000c 번지 처럼 이전의 실행내용과 무관하다면 0x0008번지 보다 먼저 실행이 될수도 있게 하는 것입니다. 물론 소프트웨어 개발자 입장에서는 이러한 문제에 신경쓰지 않아도 시스템에서 알아서 해주죠. 이것을 S/W 개발자가 모두 생각하면서 작업을 해야 한다면 엄두가 나지 않겠죠..
- Superscalar
CPU는 한 클럭에 하나씩의 명령어를 처리하게 되어있습니다. 이를 개선해서 동시, 혹은 한 사이클 미만으로 둘 이상의 명령어를 처리하는 방식으로 슈퍼스칼라 등의 방식이 나왔으며, 이는 파이프라인을 나누어 휴지 상태의 하드웨어를 활용하도록 하는 방식을 사용합니다. 이처럼 병렬연산 구조는 겹치지 않는 명령어를 병렬로 동시 진행함으로서 프로세서의 내부에서 작동을 대기하며 휴지 상태로 있는 파트를 줄임으로서 작업효율을 높여 연산 속도를 향상시키는 것에 목적이 있습니다. 명령어 스케줄을 H/W에 의존합니다. Multi-ALU 기능으로 한 클럭에 여러 명령어 들을 fetch 해서 동시에 여러 명령어 들을 실행 시킬 수 있어 CPI(Clock per Instruction)가 1보다 작아 질수도 있음. 데이터 의존성, 자원 의존성, 프로시저 의존성이 존재하는 경우에는 동시에 실행되어서는 안됩니다. 도입한 에로는 IBM RS/6000, DEC 21064, Intel i960CA 등이 있습니다.
- VLIW (Very Long Instruction Word)
VLIW는 ILP(Instruction Level Parallelism)를 최대한 활용해서 병렬 연산을 진행하며, 이를 하나의 긴 명령어 형식 내에 동시에 실행될 수 있는 명령어(연산 코드 및 오퍼랜드)들을 여러 개 포함시킴으로써 각명령어 단위를 인출해 실행할 때 마다 여러 연산이 동시에 실행되도록 하는 방식 입니다. 명령어 코드는 길지만 하나로 취급되기 때문에 인출과 해독은 하나의 회로에 의해 이루어지고, 각 연산의 실행 사이클만 여러 개의 유니트(ALU를 비롯한 Function unit)들로 나누어져 동시에 처리되게 된다. 컴파일러단에서 명령어의 배치가 이루어 지는 방식입니다. 하나의 명령어 코드의 길이가 128, 256, 512 비트단위로 구성되어 질수 있습니다. VLIW를 도입한 예로
TI C6000 Series,
ATI GPU core,
Intel Itanium 등이 있습니다.
Superscalar와 VLIW가 비슷하게 생각 되어질 수 있는데, 슈퍼스칼라(superscalar)는 CPU 내에 파이프라인을 여러 개 두어 명령어를 동시에 실행하는 기술입니다. 명령어를 동시에 실행 시키기 위해서 ALU가 여러개 있어야 합니다. VLIW는 1개의 긴 명령어 안에 여러개의 명령어들을 인출하여 동시에 실행하는 기술입니다.
(3) Cache
CPU 성능을 높이는 방법으로 요즈음 디부분의 CPU들은 Cache를 사용합니다.
캐시가 생겨나게된 배경은 일반적으로 프로그램은 한번 참조했던 명령어나 데이터는 다시 참조 할 가능성이 높다는 데서 기인 합니다. 이를 참조의 지역성 이라고 합니다. 참조할 데이터가 가까운주소의 영역에 있는 특성을 공간적 지역성(Spatial locality)라 하고 최근에 참조했던 주소를 다시 참조할 가능성이 높은 특성을 시간적 지역성(Temporal locality) 이라고 합니다. 이러한 특성을 가지고 캐시의 블럭은 최근에 참조했던 주소의 데이터를 블럭단위로 SRAM 캐시 공간에 저장을 해서 CPU에서 속도가 느린 메인메모리의 접근을 최소화 하도록 합니다.
3.2 CPU Clock 증가의 한계점
(1) Clock
2000년도 중반 이후 CPU의 클록 속도는 더 이상 급격하게 증가하고 있지 않음. 클록 속도가 증가하면 전력 소비및 누설전류 증가와 함께 심한 발열이 발생하고 이로인해 복잡한 쿨릭 시스템 설계가 필요해 집니다. 예전의 Pentium 싱글코어 CPU들의 쿨링팬을 생각하면 발열등이 어느정도 인지 짐작이 갑니다.
참고. Moore’s Law
1965년에 발표 되었고, 그 의미는 "마이크로칩의 가격은 18개월 마다 절반으로 하락" 하고
"마이크로칩의 성능은 18개월 마다 2배로 발전한다." 는 의미이다.
2000년도 중반까지 법칙이 맞아 왔으나 최근에는 성능이 2배로 발전한다는 법칙은 한계점에 도달하고 있다.
3.3 Multi Core Processor
(1) Hyper Threading
- 하나의 CPU에서 2개 이상의 Thread를 병렬적으로 수행 시킴. 엄밀히 이야기 하면 Multi Core Process는 아닙니다.
- Hyper threaded CPU는 추가적인 레지스터들 및 하드웨어가 필요 함
(2) Multi Core
- 하나의 CPU 내부에 두 개 이상의 Processor 코어를 두어 각각의 Processor에서 프로그램을 수행 시킵니다.
- Homogeneous : 동일한, 균질의 - 똑같은 종류의 CPU를 여러개 가지고 있음
- Heterogeneous
: 이종혼합(CPU+GPU) - 인텔 울트라북 등 에서 사용하는 CPU들
(3) Memory Wall
- Core 개수가 많을 수록 한 코어가 메모리를 사용할 수 있는 기회가 적어짐.
- Core의 개수가 8개 이상 증가되면, 오히려 메모리 대역폭 성능이 감소됨
(4) Parallel Programming
- Multi Core 시스템에서 성능을 높이기 위해서는
병렬 프로그래밍 효율에 달려 있음(The Free Lunch is Over)
- 인간의 보편적인 사고를 뛰어 넘어야 하는 어려움
- 컴파일러의 성능이 그다지 뛰어나지 못함
참고. The Free Lunch is Over
A fundamental turn toward concurrency in software.
예전에는 소프트웨어 개발자들이 멀티코어등을 신경쓰지 않고 개발을 해도 하드웨어 성능이 급격하게 발달이 되어 소프트웨어 성능이 개선되었으나 최근에는 무어의 법칙에도 한계점이 도달했고 마이크로 프로세서의 성능 개선의 방법으로 멀티코어쪽으로 진화하고 있어, 개발자들이 소프트웨어 성능을 개선하기 해서는 동시성등을 고려하여 개발을 해야 하지만, 이것은 쉬운 문제가 아닙니다.
- Refer to
Dr. Dobb’s Journal, 30(3), March 2005
http://www.gotw.ca/publications/concurrency-ddj.htm
4. Embedded Software
4.1 Machine & Language
(1) 기계어( Machine Code )
- Processor (CPU)가 이해하는 0과 1로 이루어진 디지털 신호
- Processor 제조사마다 코드 방식이 모두 다름
- 개발자가 기계어를 사용하여 프로그램 하는 것은 거의 불가능 : 예전에는 기계어로 직접 프로그램을 했다고 하는 분들도 계시는데 필자는 그런 정도의 세대는 아니어서 해보지는 못했지만, 생각만 해도 머리가 지끈 아파 오네요.
(2) 어셈블리어( (Assembly Code )
- 기계어 작성의 불편함을 극복하기 위해서 Processor 제조사에서 정의함.
- 처리속도가 기계어와 같음( 기계어와 1:1 로 매칭 )
- Processor Core 마다 어셈블리 코드가 다름 : ARM, MIPS, x86 명령어들 ..
- 가독성( Readability ) 이 기계어보다 훨씬 좋지만 여전히 보통이 개발자에게는 쉽지 않음
(3) C Language
- Assembly 명령어들의 단점을 극복한 언어
- 임베디스 S/W 개발에 가장 많이 이용됨
- 어셈블리보다 가독성이 매우좋고 관리가 편함
- 구조적, 모듈화 프로그래밍 가능
- 어셈블리처럼
하드웨어 직접제어 가능
4.2 컴파일러
(1) C언어 번역기
- C로 표현된 언어를 어셈블리로 번역하고 오브젝트 파일로 변환 시킨다.
- 사용하려는 Processor코어에 맞는 컴파일러를 사용해야 함
- C로 표현된 프로그램을 ARM코어 CPU 에서 동작시키기 위해서는 ARM 컴파일러를 사용 해야 함. 보통은 x86 PC에서 개발(코딩) 한후 ARM용 컴파일러를 이용해서 컴파일을 한후 타겟이 되는 ARM CPU 에 다운로드(퓨징) 하여 실행 시킴. x86 PC에서 사용하는 ARM용 컴파일러를 Cross Compiler 라고 함. ARM용 크로스 컴파일러로는 KEIL MDK, IAR Workbench(EWARM), ADS, RVDS, ARM용 GCC(주로 리눅스 개발환경에서 사용) 등이 있음.
(2) 오브젝트 파일
- 어셈블리 코드 섹션, 데이터 섹션
- 디버깅 정보
- 심볼 정보
4.3
어셈블러
어셈블리 언어를 기계어(오브젝트 파일)로 변환 합니다. 어셈블러와 어셈블리 언어를 혼동하면 안됩니다. 어셈블리 언어는 코드를 작성하는 언어이고, 어셈블러는 작성된 어셈블리 언어를 기계어로 변환 시키는 역할을 합니다.
4.4 Linker
- 여러 코드및 데이터 섹션들에 미리 정의된 주소를 할당합니다.
- 이미 빌드된 라이브러리들이 함께 사용 될 수 있습니다.
- 링크 작업시 같은 속성의 섹션들(.text, .ro, .rw)을 같이 묶어주는 작업도 합니다.
여기까지 컴파일러, 어셈블러, 링커등 각각이 하는 일들을 살펴 보았습니다. 그렇다면 컴파일하고, 어셈블하고, 링크작업까지 완료가 되면 생성되는 실행가능한 Binary 는 어떤 구조로 해서 만들어 지는 것일까요. 아래 그림을 통해서 알아 보도록 하겠습니다.
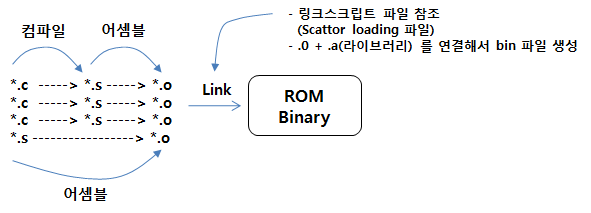
*.c 파일을 컴파일 하면 *.s 파일이 생성되고 *.s 파일을 어셈블 하면 *.o 파일이 생성이 되고 *.o 파일들과 다른 라이브러리 파일들(*.a) 을 Link 시키면 실행 가능한 bin 파일이 생성이 됩니다.
그러면 Linker는 여러개의 *.o 파일들을 어떻게 묶어서 bin 파일을 생성하는 걸까요? 이것을 알려면 *.o 파일의 구조와 링크스크립트 파일에 대해서 알아야 합니다. 링크스크립트 파일은 나중에 다시 이야기 하도록 하고 우선 *.o 파일에 대해서만 자세히 보도록 합시다.
아래 일반적이 *.c 파일이 있습니다. 각 변수들과 함수들이 메모리 상에 어떻게 자리를 잡는지 RO, RW, ZI 영역으로 구분해 보세요.
참고로 0 으로 초기화 되거나 값이 할당되지 않은 변수는 ZI(Zero-initialized) 영역,
초기값이 전역 변수는 RW(read-write) 영역,
코드나 변경 불가능한 변수는 RO(Read only) 영역으로 할당이 됩니다.
RW, ZI, RO는 GCC 등에서는 각각 .data, .bss, .constdata + .text 로 불리기도 합니다. 즉 RW = .data, ZI = .bss, RO = .constdata + .text 가 됩니다.

정답은 아래와 같습니다. 아래 오른쪽 그램에 있는 표의 내용이 바로 C코드가 컴파일 되어 오브젝트(*.O) 파일의 구성이 되는 것입니다.

여기서 중요한 사실은 함수, 전역변수, static 변수는 자기만의 주소를 가지며 Map 파일에 Symbol 형태로 나타나며, Local 변수는 자기만의 주소를 갖지 못합니다.
Symbol들이 자기만의 고유 주소를 갖고 있기 때문에 다른 파일의 함수들에서도 직접 access가 가능한 이유 이기도 합니다.